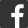在沒有利用BI(商業智慧)搭建完備的資料分析結構前,企業都是按照傳統的方式來實現業務資料需求,就是各部門將自己的需求提給信息化部門去做。
但「技術問題一股腦的扔給IT部」的方式,溝通成本高、需求響應慢。在倡導「人人都是資料分析師」的年代,是很低效的配合方式。
自助式BI工具可以解決這些問題。
我們可以試著將企業涉及資料分析的人群分為兩大類:
1、資料管理員
這部分人群掌握著資料庫、資料倉儲,對基礎資料擁有設計和建模能力。針對他們,BI可以作為一個平台幫助連接各資料庫、資料倉儲。管控、整合、清洗資料,為有分析需求的人準備資料,在分析過程中自動建模。功能上力求做到——高速度高性能、穩定。
2、分析使用者
針對深度分析使用者,他們往往就有資料分析基礎和理解模型的能力,對資料有再處理加工和深度分析挖掘的需求。此時BI更多充當快速視覺化分析的工具,通過視覺化輔助資料分析時的思考。
針對初級分析使用者,他們的需求往往是Dashboard即席分析,結合視覺化有主題的展示業務資料,實時監控,預警分析。此時的BI最好能有較低的上手門檻,能快速取數。
針對一些查看資料的使用者,比如領導boss們,他們的訴求就是看報告,了解業務狀況,輔助業務決策。BI要做到報告可讀美觀,讓使用者聚焦於理解儀錶板要表達的資料含義。
也正是基於以上的實際資料分析場景,FineBI 5.0做了煥然一新的升級。聚焦於兩個環節,資料的分發和資料的分析。
資料的分發
基於資料安全和精細的許可權管理,讓科技部門放心的把資料許可權下放,業務部門能完整方便的拿到所需資料,這是自助分析推行的根基。
資料的管理是阻礙企業資料分析推行的很大原因。科技部門擔心風險,導致業務部門很簡單的需求不能得到及時響應;很多資料的需求本身時效性很高,一旦過了這個資料再拿到也已經沒有價值了;還有部分是資料給的不完整,臟資料很多,導致業務想進行的分析做到一半進行不下去,逐漸放棄…
資料的分析
好的工具能提高效率,優化協作方式。FineBI 5.0想讓人人都能成為資料分析師:業務能夠很容易的對資料進行分析和觀察,甚至一定程度的專業分析;專業的資料分析師能夠藉助BI,更高效的處理資料做分析。
最低成本的發現資料價值,也是FineBI 5.0最核心解決的問題。
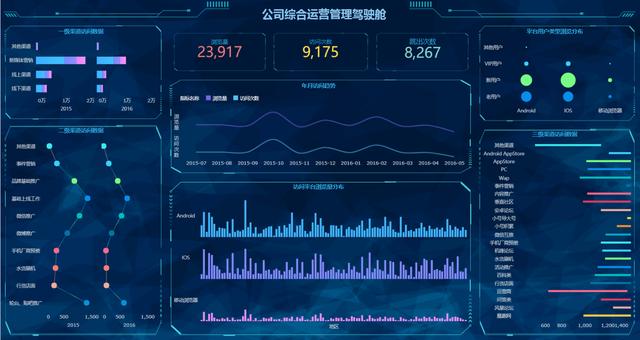
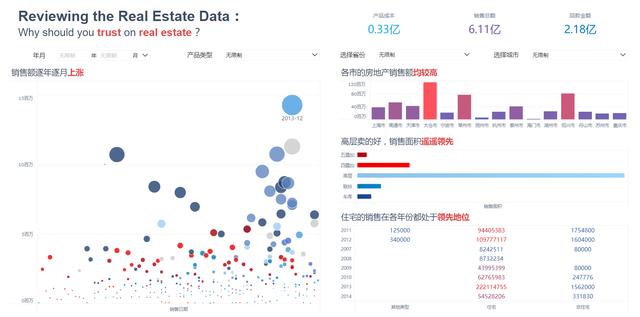
FineBI 5.0可以說是真正能夠覆蓋「個人資料分析」到「企業資料價值挖掘」的資料分析平台。
新版本賦予了其4類特性:資料分析挖掘、資料處理、大數據高性能、企業級資料管控。
資料分析挖掘
1、更符合人類思維的探索分析——step by step
資料分析思考過程不可能是一步到位的,一定是分析——發現問題——修正的螺旋上升的過程。我們發現使用者在拿到資料時,都先是嘗試性的分析看一下資料的趨勢,然後在逐漸一步一步地去深入分析。在這過程中,有可能很多思考是錯誤的,有些指標是需要再計算的。對於這些「探索性」的操作,FineBI提供增加,修改,刪除歷史操作功能,及時修正,每一個步驟都可以預覽資料。且提供無限層級的資料分析:使用者可以對自己許可權下的資料任意處理。
2、分析思維主導的視覺化
5.0的視覺化分析,採用全新的設計理念。基於著名的圖形語法(The Grammar Of Graphics)設計改良,提供了無限的視覺分析可能,我們稱之為「無限圖表類型」。
取消了傳統圖表類型的概念,取代以’形狀’和形狀對應的’顏色’,’大小’,’提示’,『標籤』等屬性;取消了’分類’、’系列’等概念,取代以’橫軸’、 ‘縱軸’兩個方向。當你分析兩個資料欄位的相關性時,會自動選擇最合適的圖表(也可手動調整)。這樣的思維更符合大家拿到資料不知如何分析,先初步了解資料情況的探索式分析場景。
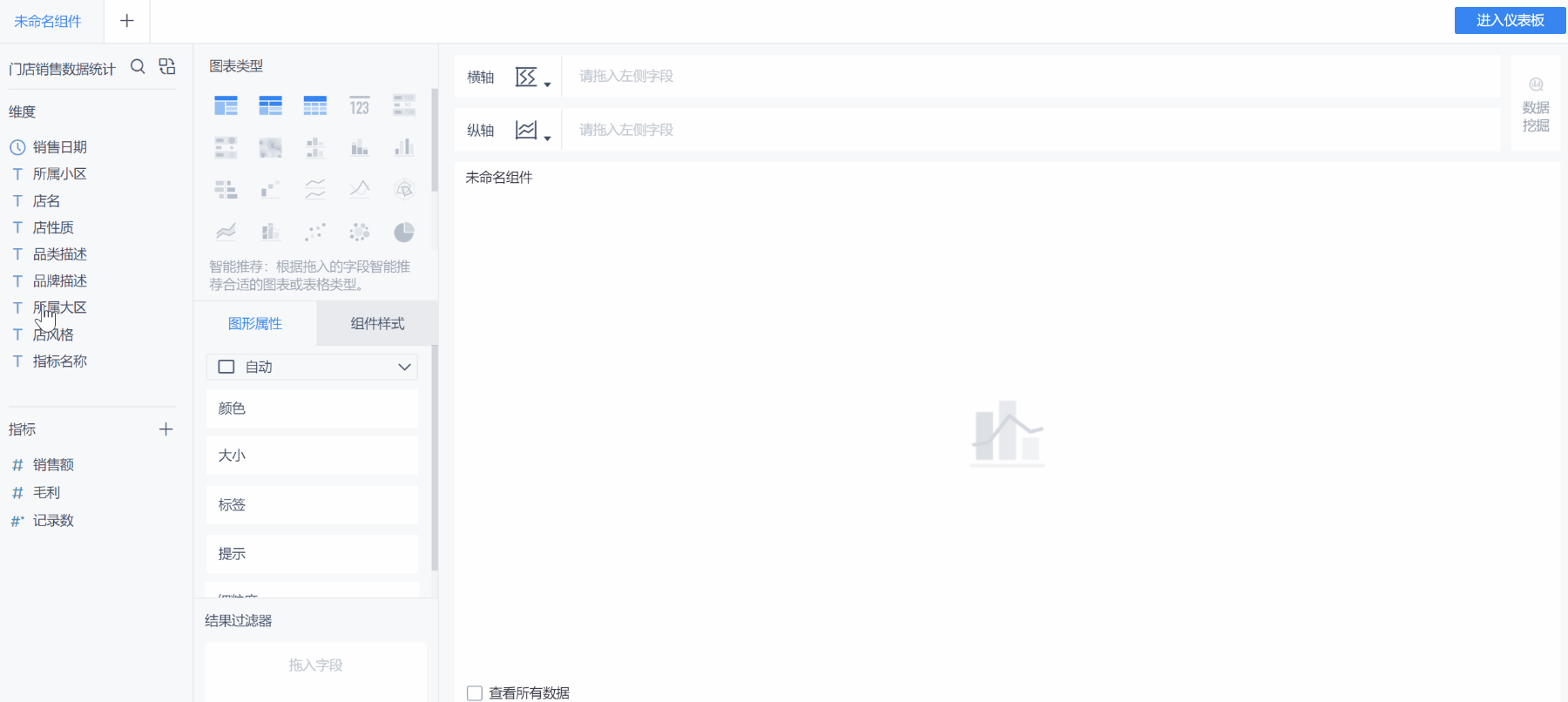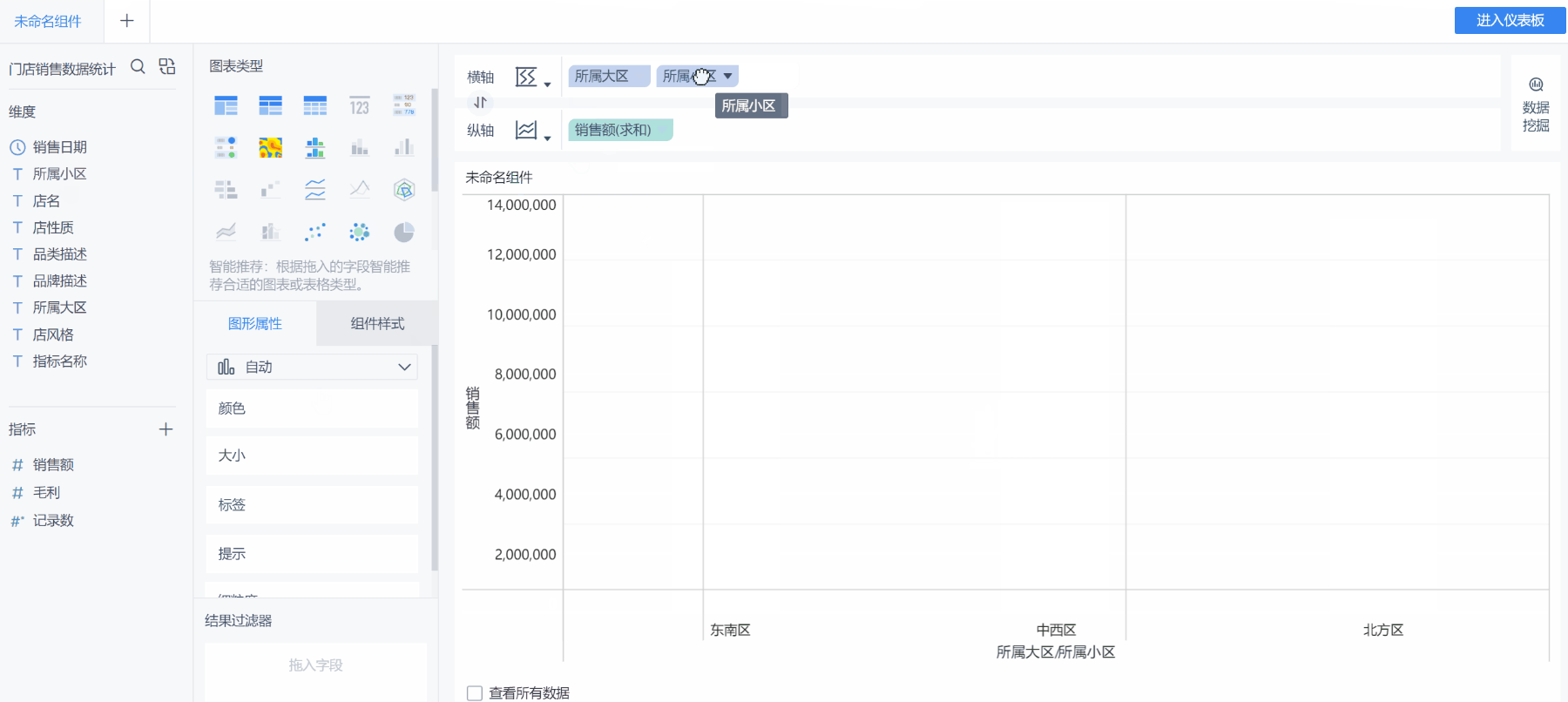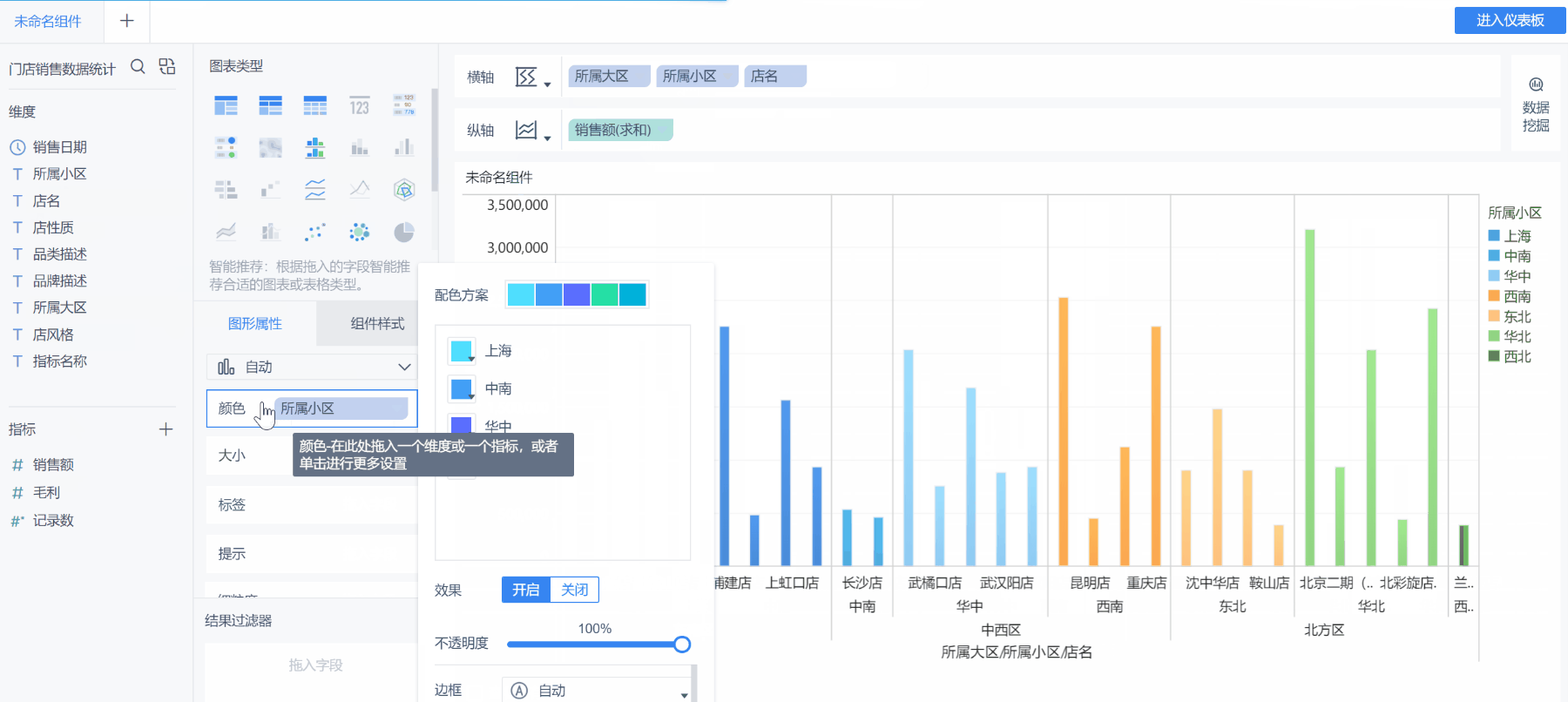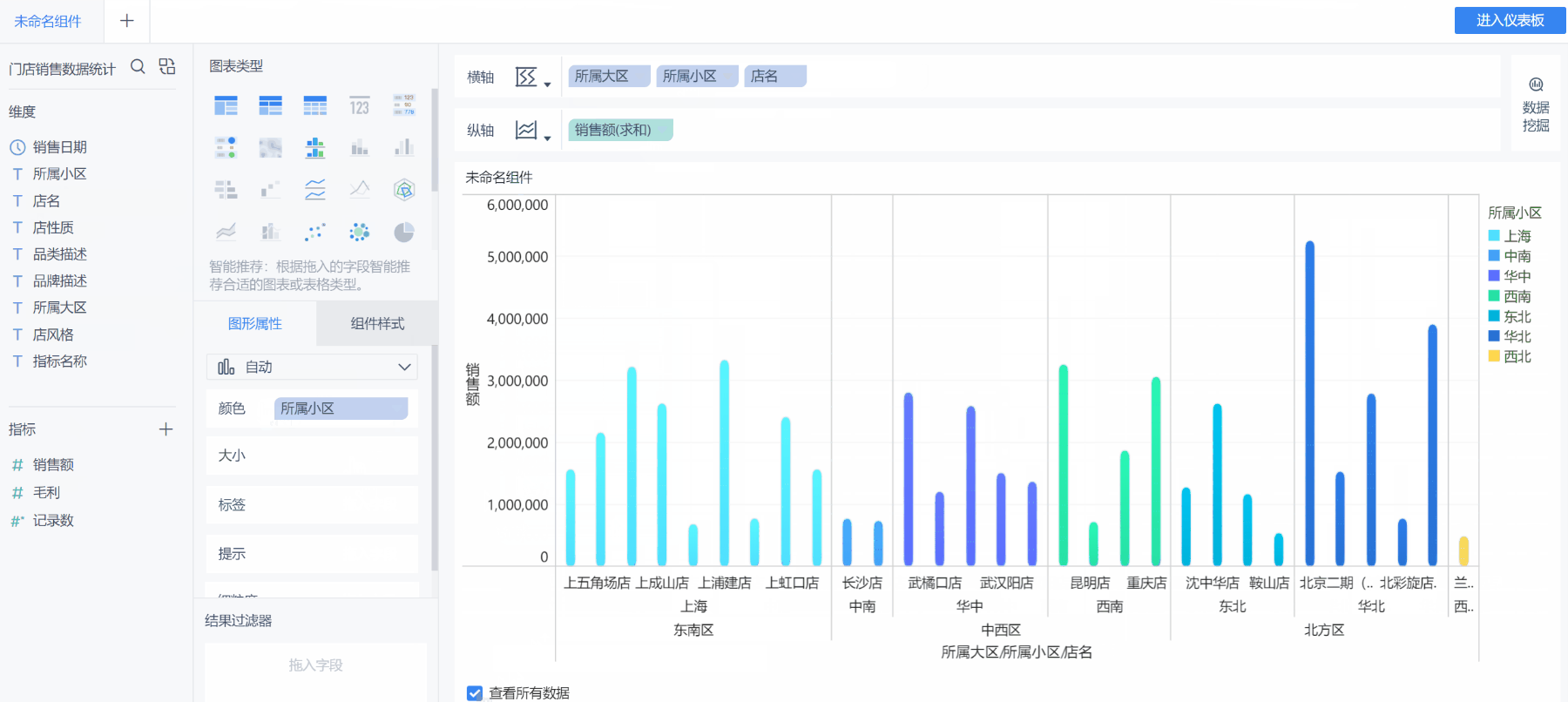
每種圖表背後都有很強的資料分析演算法,讓分析更加專業科學。此外FineBI 5.0還優化了底層資料邏輯,重新設計了圖表的大數據模式,支撐圖表展示資料量可達百萬以上。
一些FineBI 5.0實現的視覺化效果:
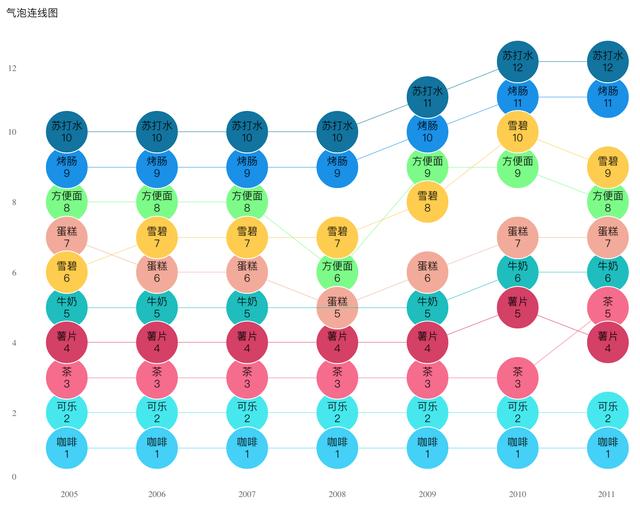
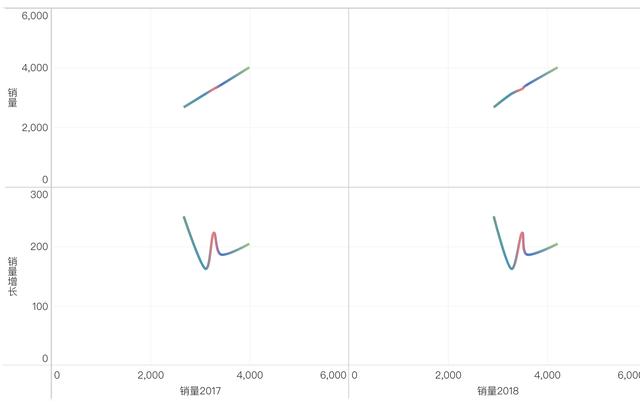
3、新增資料探勘演算法
在5.0版本中,增加了五類挖掘演算法,分別為時間序列、聚類、分類、回歸和關聯規則。
也就是說,在這一版本中,如果你想預測未來的銷售額,你想智慧地給使用者群分類,或者你想知道簡訊發給哪個使用者獲得的反饋可能性比較大,將會成為現實。
此外,我們將時間序列演算法和聚類演算法和圖表分析相結合,不用寫任何演算法程式碼只需要簡單的拖拖拽著就可以立馬看到預測和聚類的結果。
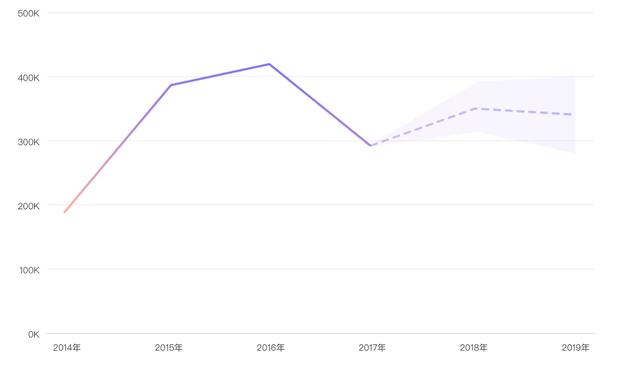

如果需要更多的演算法怎麼辦,我們當然為這種複雜的挖掘需求做好了準備, 5.0可以集成了R語言,可以直接在FineBI中進行R語言編譯,實現資料統計和分析的需求。並且直接將資料統計和分析結果通過finebi展現,完美的結合了R語言的統計能力優勢和FineBI的展現優勢。
當然,以上還只是開始,未來還會增強FineBI的資料探勘能力,開發更多的內置演算法,讓資料探勘更為簡單易用。
資料處理
讓業務人員拿到需要的資料,讓IT部門放心的提供資料,是自助分析推行、人人都是資料分析師的根基。FineBI 5.0資料準備功能整合了原SPA螺旋分析和ETL,並做了進一步的增強,更方便、更高效、更強大,業務人員可以在精準的資料許可權下,實現對資料進行再處理和深度分析挖掘的需求。
(1)清晰全面的資料掌控。FineBI 5.0可以讓使用者對自己的資料,有更全面、更清晰的了解。表結構和表預覽兩種檢視表,讓表基礎信息查看更清晰、更方便,大面積的資料預覽區域,更易了解資料內容。資料血緣分析功能,讓使用者對資料的來源去向、應用狀況一目了然。同時,資料的更新情況,何時更新、更新頻繁程度,也能直觀展示。
(2)簡單高效的資料配置。高效的資料準備和配置,可以減少使用者不必要的麻煩。關聯智慧繼承,可以自動對新創建的分析表建立關聯,延續資料關聯關係。在基礎資料更新時,將自動觸發分析使用者的資料更新。根據資料量、使用頻率以及實時性的要求,能實現實時資料和抽取資料的無縫切換,完全不影響使用者已經做好的分析。
(3)強大友好的資料處理。使用者可以對自己的資料進行任意處理,即便是已經參與分析的資料也一樣,進行如清洗過濾、新增欄位、表合併、排序、分組匯總、資料探勘等操作,來得到自己想要的資料。每一步操作都有資料預覽,操作後立即收到反饋,增強使用者的資料操縱感,減少不確定性。
大數據高性能
5.0將直接對接資料庫的實時資料引擎與抽取資料的引擎整合統一為Spider計算引擎。使用者可以根據資料量、實時性要求、使用頻次等,自由選擇實時或抽取的方式。實時資料與抽取資料方式的無縫切換,將更加靈活高效支撐前端的高性能分析。
Spider資料引擎可靈活支撐不同資料量級的分析,在資料量激增之後,可橫向擴展機器節點,利用Spider引擎專為支撐海量大數據分析而生的分布式方案。
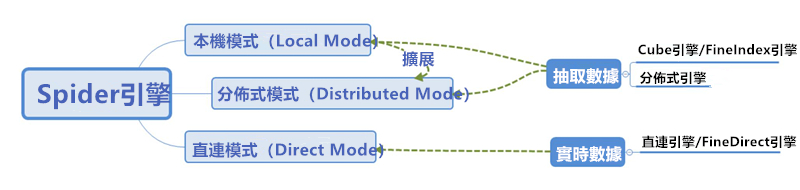
Spider引擎分布式方式,結合Hadoop大數據處理思路,以最輕量級的架構實現大數據量高性能分析。此分布式方案集成了Alluxio 、Spark、 HDFS、zookeerer等大數據元件,結合自研高性能演算法,欄式儲存、並行內存計算、計算在地化加上高性能演算法,解決大數據量分析問題與在FineBI中快速展示的問題。同時從架構上保證了計算引擎系統全年可正常使用。
優勢:
(1)引擎支撐前端快速地展示分析,真正實現億級資料,秒級展示。
(2)使用者可以根據資料量、實時性要求、使用頻次等,自由選擇實時或抽取的方式,靈活滿足實時資料分析與大數據量歷史資料分析的需求。
(3)抽取資料的高性能增量更新功能,可滿足多種資料更新場景,減少資料更新時間,減少資料庫伺服器壓力。
(4)合理的引擎系統架構設計可保證全年無故障,全年可正常使用。
企業級資料管控
資料管控能力決定BI工具的應用範圍和深度。FineBI 5.0提供了精準的企業級資料許可權管控方案,管理員可以高效便捷的進行許可權配置,放心大膽的交付給分析人員相關資料,無需擔心隱私資料泄露。
(1)許可權統一配置。平台統一控制許可權,如業務包許可權、資料錶列許可權、資料表欄許可權等,許可權控制的粒度更細緻,更科學。通過配置主表許可權,所有關聯的業務表許可權也會生效。
(2)許可權智慧繼承。分析人員所做的分析表預設繼承基礎資料的許可權,管理員無需再擔心這些資料表的許可權分配,每個閱讀使用者自動看到自己許可權範圍內的資料,這有利於促進分析人員之間的分享和交流。
(3)滿足不同場景。不同場景對資料許可權的要求是不同的,每個使用者有權將自己許可權範圍的資料,在有需要的情況下開放給其他使用者。比如總部製作的各大區的匯總銷售額,想要讓每個使用者都可以看到,許可權繼承的情況下,各大區是沒有許可權看到其他大區的資料的,但是總部的分析表製作使用者有權不繼承許可權,將資料開放給各大區使用者。
最後
此次的FineBI 5.0版,煥然一新,將企業級自助式BI工具提升到一個新的高度。不僅是資料分析挖掘工具、資料視覺化工具、更是適合多數企業複雜流程下的資料分析平台。
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!