資料分析是一個龐大的工程,有的時候過於抽象且依賴經驗。本文是軟妹對學習和實踐資料分析的一個總結,希望提供一種通用的資料分析思路,並在分析思路的每個步驟中介紹相關的分析演算法及其應用場景,對於演算法只做淺層次的介紹,待讀者在實際使用中自行深入瞭解。
本文主要針對剛剛接觸資料分析或者面對一堆資料不知道如何下手的讀者,經驗豐富的資料分析師們可以略讀。同時,本文介紹的分析思路由於筆者的經驗和知識有一定的局限性,希望讀者在分析中合理參考。
在進行資料分析之前,首先應該做好以下準備:
一、熟悉業務、瞭解資料來源
這一點是資料分析的前提。資料分析,除了我們面對的資料之外,更多的是這些資料背後隱藏的各種業務。例如當我們看到使用者的消費記錄時,它可能不僅僅是收銀系統購買商品,還包含了為了會員系統的滿減而做的湊單,活動管理系統的開業折扣商品,或者是推薦系統的推薦商品。對於業務深入的瞭解,有助於更好的發現分析的維度,快速鎖定問題和原因。
二、明確分析的目的
資料分析不是模型演算法和視覺化的堆砌,而是有目的地發現某種現象,支撐某些決策。所以在分析之前,一定要明確自己分析的目的,切忌照搬其他的專案的分析內容,或者隨意組合手上的分析模型演算法,這樣會導致分析結果華而不實。
三、多視角觀察
要想達到某種分析目的,需要從多個視角觀察資料,這樣不僅可以對資料整體有個全面的瞭解,也有助於發現潛在的資訊。例如當我們需要找出潛在的會員的時候,最直接的當然是消費比較多但還不是會員的人。但從促銷活動的角度看,那些熱衷購買打折商品的人很大概率也是潛在的會員,因為加入會員他們會獲得更多的折扣,這是他們希望的。同時,從推薦系統的角度看,那些對推薦系統推薦的商品滿意的人,也不太會拒絕你推薦他加入會員。
做好準備工作後,接下來就進入正題,開始分析:
一、它是什麼?
資料分析一定是針對某一些物件的,就像消費記錄針對的是某一店鋪。那首先要做的,就是通過資料來描述這一物件。就像瞭解一個人一樣,首先要瞭解他是個怎樣的人,然後便是他的特點,比如我的一位朋友是個學霸,他的特點就是每晚學習到12點,每科成績基本滿分。所以,主要從兩個方面關注一個物件,整體描述和特徵:
基礎統計
統計是最直接的方法,而且應用起來也很簡單。常用的方法有總和、平均數、最大最小值、中位數、方差、增長率、類型占比、分佈、頻率頻次等等。這裡不多做介紹。
聚類
“物以類聚,人以群分”,聚類屬於非監督學習,聚類可以將一組資料分成多個類別,每個類別內部的資料相似,但兩個類別之間相異。聚類有助於發現資料分佈上的特點,可以大量減少分析的資料量。比如在軌跡分析和預測中,通過聚類,我們會發現某個人主要出現在三個地方,宿舍周圍、食堂周圍、教學樓周圍,那麼當我們預測他在哪的時候,就可以從對無數經緯度座標的分析變成對三個地點的分析。
特徵分析
特徵工程是很龐大,正如描述的那樣,資料和特徵決定了機器學習的上限,而模型和演算法只能逼近這個上限而已。特徵工程包含了特徵提取和特徵選擇,由於其演算法眾多且比較複雜,這裡不一一介紹。特徵分析首先要明確分析的單位,包括時間、空間和類型等等。就像軌跡預測中,分析每十分鐘的所在地要比分析每秒鐘的經緯度座標要實際得多,而分析每小時的所在地又太過粗糙。然後就是特徵提取,特徵提取的演算法有很多,線性的PCA(主成分分析)、LDA(線性判別分析)、ICA(獨立成分分析),文本的F-IDE、期望交叉熵,圖像的HOG、LBP等。特徵分析的主要目的是降維、減少冗餘,提高存儲計算能力。舉個不太恰當的例子,比如我們要描述二氧化碳的化學特性,有顏色、氣味、酸性、鹼性、氧化性、還原性、熱穩定性等等,同樣一氧化碳也一樣,那這時候我們把這些特性降維到C和O上,那麼認為由C和O的組成的一氧化碳和C和2個O組成的二氧化碳有相似的特性,都是無色無味的氣體。
二、它發生了什麼?
它發生了什麼包涵正常和異常,而我們通常會更加關注異常,這裡也著重於異常分析。它發生了什麼與它是什麼在分析思路和方法上是一致的,只是針對不同的階段,比如時間上本月與上月。對於異常分析,主要有兩部分,發現異常和推送預警。推送預警比較簡單,只要注意預警的級別和推送的人。而異常發現,除了能直接觀察的異常,比如我們的學霸這次居然有一科沒及格,更多的需要注意暗物質。所謂暗物質,就是無法直接觀測的現象和關聯。還是拿我們的學霸君說,這次他依舊像往常一樣全部考了滿分,這是正常的,然而我們發現他這次考試的複習時間只有以往的一半,這就不正常了,而我們又發現這次考試題目很簡單,所以這又正常了?錯,它依舊是異常,因為考試前學霸君並不知道考試的難度,所以對於複習時間減半依舊是異常。所以,重要的事說多遍,一定要熟悉業務和多視角觀察。
在異常判斷的時候,通常會根據具體的業務設置一些係數,通過這些係數的突變來發現潛在的異常。回到剛剛那個例子,我們可以簡單的用成績與複習時間的比值作為係數。這些係數在軌跡分析中尤為重要,例如我們要分析一個人的軌跡是否異常,首先會看他是否出現在從來沒去過的地方,如果沒有,第二步則用一個軌跡的向量去分析。例如通過聚類,我們的學霸君主要出現在教室、圖書館、寢室三個地方,每個地方呆的時間假設都是每天8小時,那這時候就形成一個(8,8,8)的向量,而今天學霸的向量是(2,2,20),通過計算兩個向量的距離來發現異常,通常是歐式距離和余弦距離。
三、為什麼發生?
每當發生什麼的時候,我們都會問一句為什麼?為什麼是對資料的深層次挖掘與診斷,精確的問題診斷有利於正確的決策。一般可以用到以下的方法:
趨勢、同比環比
這是很簡單的方法,既觀察其過去和其他週期的情況,這裡不多介紹。
下鑽
下鑽絕對是最常用且有效的找原因的辦法,既一層層抽絲撥繭,直到找到最根源的原因。只是在下鑽的過程中,一定要注意下鑽的區域和方向,就像挖井一樣,並不是隨便找個地方向任何方向打下去就會出水的。就拿某商場的銷售額下降來說,要找出銷售額下降的原因,首先會想到去找那些銷量減少最多的商品,比如我們發現咖啡減少最多,為什麼咖啡減少呢,因為氣溫變高,人們更偏愛冷飲了。但是對比去年前年,每年這個時候咖啡都會減少,而取而代之的是冷飲的增加,它恰好彌補了咖啡的減少。所以這時我們需要變化思路,去尋找那些以往銷量很好而當下銷量很少的產品。而為了不犯上述的錯誤,我們可以分為多個層次下鑽,既一開始只關注大的分類的變化,如服裝、飲食等等,再從變化較大的類開始繼續下鑽。
相關分析
相關分析是對不同特徵或資料間的關係進行分析,發現業務的關鍵影響和驅動因素。例如時間到春運了,車票就不好買了一樣。相關分析常用的方法有協方差、相關係數、回歸和資訊熵等,其中相關係數和回歸也可以用於下面將會提到的預測。其中相關是回歸的前提,相關係數表示了兩個變數有關係,而回歸則表示兩個變數是何種關係。其中相關係數與回歸也可以延伸到典型相關分析(多元)與多元回歸。例如經典的“啤酒和尿布”,如果想要知道啤酒銷量為什麼增加,可以分析下它與尿布銷量的相關性。
四、它還會發生什麼?
它還會發生什麼就是純粹的預測了,預測的演算法有很多,但也並不是說所有的預測都需要借助難以理解的演算法。比如萬精油的趨勢、增長率、同比環比、基本概率等,有的時候就很能說明問題。但在這裡,還是介紹一些常用的預測方法:
特別的點
對於即時性和連續性要求不高的預測,這絕對是最省心省力的辦法,但是這與具體的業務深度掛鉤,所以,重要的事說多遍,一定要熟悉業務和多視角觀察。比如,我有件事情必須要給我的領導當面彙報,然而他經常不在辦公室,不是在開會就是去現場了,或者正在哪見某個客戶,然而清楚的是,他每天早上8:30-9:00之間一定會來公司打卡,那我只要這段時間在打卡機旁候著就一定能見上他一面。
分類與回歸
分類與回歸都是通過已知的資料構建和驗證一個函數f,使得y=f(x),對於未知的x,通過f預測y,不同在於回歸的輸出是連續的而分類的輸出是離散的。例如,我們預測明天的溫度是回歸,而預測明天是下雨天還是晴天則是分類。分類方法有邏輯回歸、決策樹、支援向量機,而回歸一般會用到線性回歸。
當然,預測演算法還有很多,比如隱瑪律可夫(HMM),最大熵,CRF等等,這裡也不做過多的介紹。只是需要根據預測的資料的具體情況選擇正確的方法,這些可以從我們的演算法工程師們那裡得到很好的建議,當然前提是我們要將資料的特點和需要預測的東西準確的告訴他們。
五、該怎麼辦?
該怎麼辦是資料分析的最終目的。大多數情況下,當知道了問題出在哪,為什麼出這個問題的時候,都知道接下來該怎麼辦了。那麼接下來就介紹一些即使知道哪出問題了也不知道該怎麼辦的時候可以用的方法:
擬合與圖論
這是在做路線規劃的時候最常用的,比如某商場頻發商品被偷的事件,我們發現有幾個地方的商品特容易被偷,那可以將這些地方串連起來,擬合成一條巡邏的路線給保安。同樣,也可以通過構建圖並用求最短路徑的演算法(Dijkstra、Floyd等)構建巡邏的路徑。
協同過濾
協同過濾屬於是利用集體智慧的辦法,就像那個經典的面試題一樣,當你遇到一個誰也沒遇到過的問題時,你該怎麼辦?那就是問那些比你更厲害的人他們會怎麼辦。協同過濾最多的是用在推薦引擎之中,一般的方式是尋找一個使用者的n個相似用戶,然後推薦給這個用戶他相似使用者喜歡的產品,或者找到當前使用者喜歡的前n個物品,然後挑選出和這n個物品相似的m個物品推薦給當前用戶。即使不用在推薦,它的思想也很容易延伸在其他方面,比如一個新手偵探不知道這個案件怎麼破,那可以去看看柯南君類似的案件破案的步驟。
還有一種情況,也是資料分析師很常見的。就是當拿到資料,卻完全沒有目的,也就是探索性分析。這種情況借助資料分析工具,做一些大致的探索性分析,看一下資料趨勢,逐步深入。
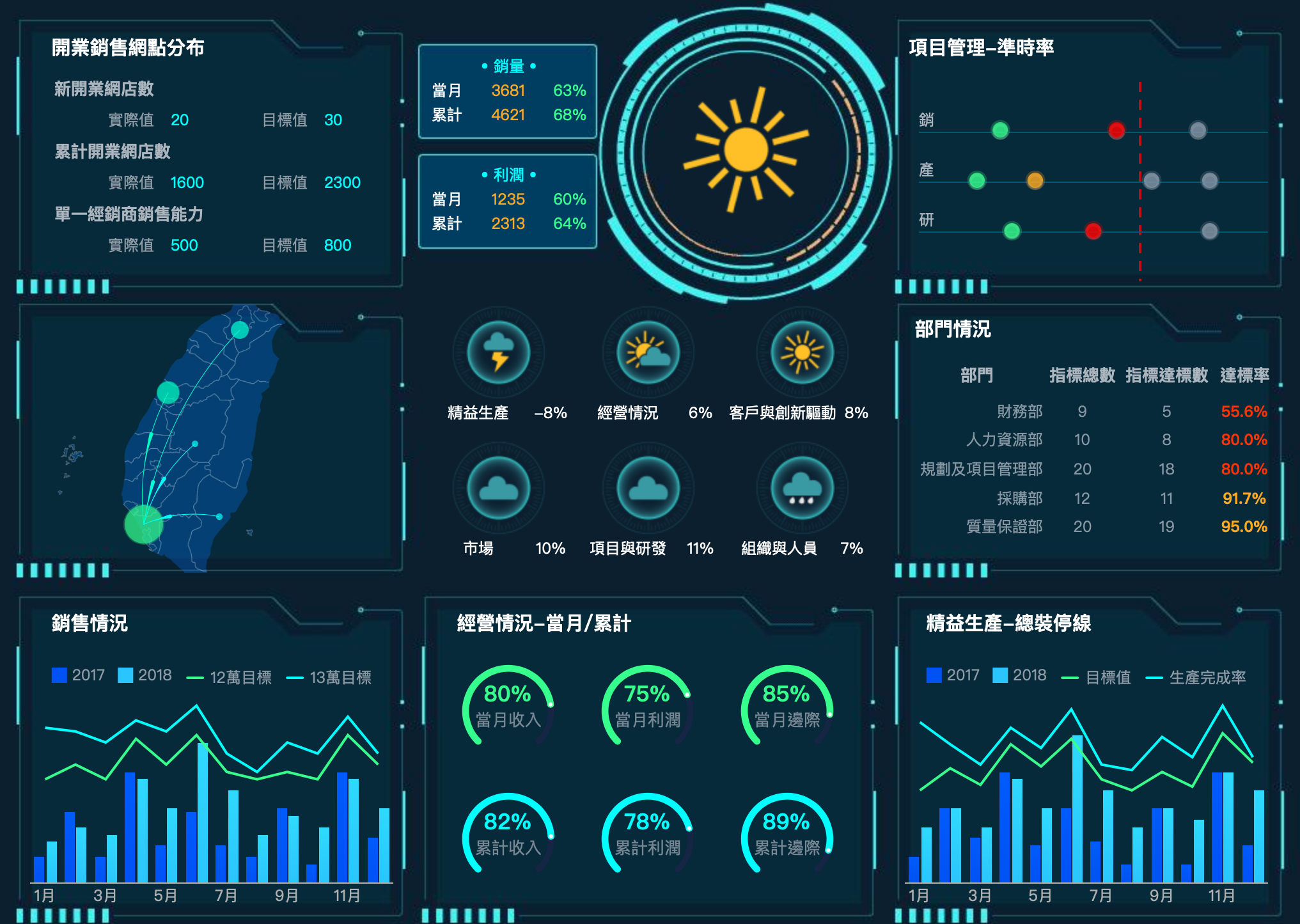
對於公司而言,探索性分析的工具主要是報告和BI。 一個完美的例子是FineReport,它可以生成各種複雜的報告,以及用於資料視覺化的大螢幕。在報告和商業智慧的基礎上,可以增加預警系統,如提醒異常指標,使領導者只需關注這些指標,而不必查看所有指標,以節省時間,提高效率。 如有必要,我們可以查看相應的報告或BI表示,這是企業探索性分析的應用方法之一。

免費試用FineReport10.0>
以上介紹的,是資料分析中的一個常規思路和可以用到的一些常規的方法。希望對妳們有所幫助,同時,不恰當的地方,也煩請批評指導(可以在臉書留言呀)。最後再次強調,資料分析不是演算法與視覺化的堆砌,需要我們對業務深入的瞭解。
如果您還想獲得更多的知識與技巧,成爲一個更好的資料型人才,不要忘記追蹤我們的臉書呀!
熱門閱讀:
我是如何入門並成爲資料分析師的?
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!