說起大數據分析,很多人都能聊上一會,但要是問大數據核心技術有哪些,估計很多人就說不上一二來了。
從機器學習到資料視覺化,大數據發展至今已經擁有了一套相當成熟的技術樹,不同的技術層面有著不同的技術架構,而且每年還會湧現出新的技術名詞。面對如此龐雜的技術架構,很多第一次接觸大數據的小白幾乎都是望而生畏的。
其實想要知道大數據有哪些核心技術很簡單,無非三個過程:取資料、算數據、用數據。這麼說可能還是有人覺得太空泛,簡單來說從大數據的生命週期來看,無外乎四個方面:大數據獲取、大數據預處理、大數據存儲、大數據分析,共同組成了大數據生命週期裡最核心的技術,下麵分開來說:
一、大數據獲取
大數據獲取,即對各種來源的結構化和非結構化巨量資料,所進行的採集。
資料庫採集:流行的有Sqoop和ETL,傳統的關係型資料庫MySQL和Oracle 也依然充當著許多企業的資料存儲方式。當然了,目前對於開源的Kettle和Talend本身,也內建了大數據內建內容,可實現hdfs,hbase和主流Nosql資料庫之間的資料同步和內建。
網路資料獲取:一種借助網路爬蟲或網站公開API,從網頁獲取非結構化或半結構化資料,並將其統一結構化為本地資料的資料獲取方式。
文件採集包括即時檔採集和處理技術flume、基於ELK的日誌採集和增量採集等。
二、大數據預處理
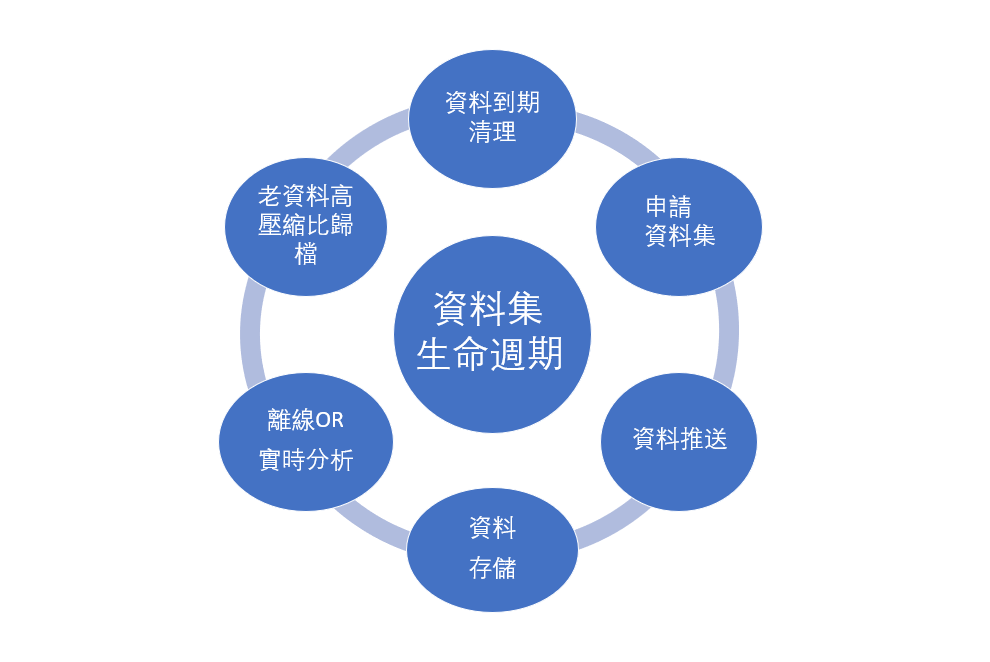
大數據預處理,指的是在進行資料分析之前,先對採集到的原始資料所進行的諸如【清洗、填補、平滑、合併、規格化、一致性檢驗】等一系列操作,旨在提高資料品質,為後期分析工作奠定基礎。資料預處理主要包括四個部分:資料清理、資料集成、資料轉換、資料規約。
資料清理:指利用ETL等清洗工具,對有遺漏資料(缺少感興趣的屬性)、噪音資料(資料中存在著錯誤、或偏離期望值的資料)、不一致資料進行處理。
資料內建:是指將不同資料來源中的資料,合併存放到統一資料庫的,存儲方法,著重解決三個問題:模式匹配、資料冗餘、資料值衝突檢測與處理。
資料轉換:是指對所抽取出來的資料中存在的不一致,進行處理的過程。它同時包含了資料清洗的工作,即根據業務規則對異常資料進行清洗,以保證後續分析結果準確性
數據規約:是指在最大限度保持資料原貌的基礎上,最大限度精簡資料量,以得到較小資料集的操作,包括:資料方聚集、維規約、資料壓縮、數值規約、概念分層等。
三、大數據存儲
大數據存儲,指用記憶體,以資料庫的形式,存儲採集到的資料的過程,包含三種典型路線:
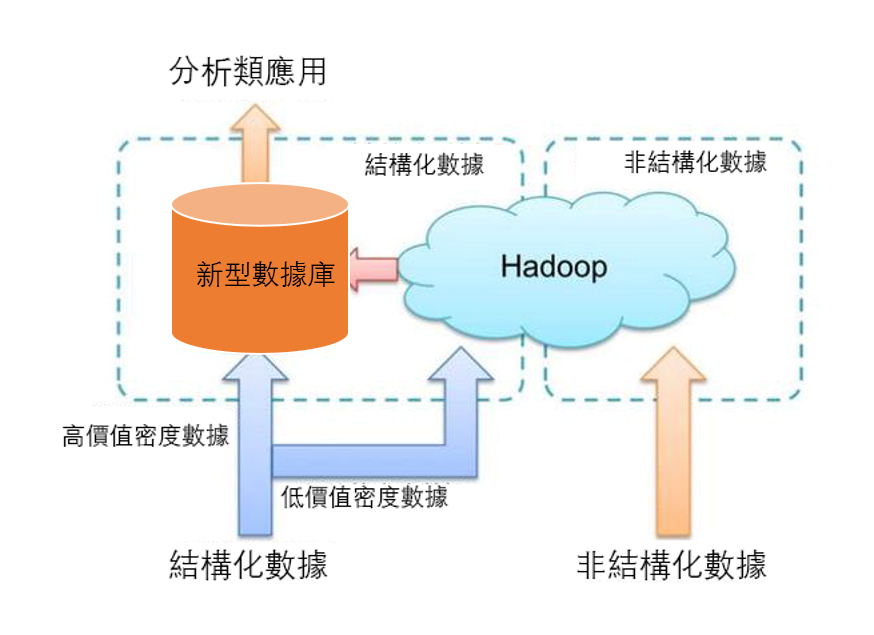
基於MPP架構的新型資料庫叢集
採用Shared Nothing架構,結合MPP架構的高效分散式運算模式,透過列存儲、粗細微性索引等多項大數據處理技術,重點面向行業大數據所展開的資料存儲方式。具有低成本、高性能、高擴展性等特點,在企業分析類應用領域有著廣泛的應用。
較之傳統資料庫,其基於MPP產品的PB級數據分析能力,有著顯著的優越性。自然,MPP資料庫,也成為了企業新一代數倉的最佳選擇。
基於Hadoop的技術擴展和封裝
基於Hadoop的技術擴展和封裝,是針對傳統關係型資料庫難以處理的資料和場景(針對非結構化資料的存儲和計算等),利用Hadoop開源優勢及相關特性(善於處理非結構、半結構化資料、複雜的ETL流程、複雜的資料採擷和計算模型等),衍生出相關大數據技術的過程。
伴隨著技術進步,其應用場景也將逐步擴大,目前最為典型的應用場景:透過擴展和封裝 Hadoop來實現對互聯網大數據存儲、分析的支撐,其中涉及了幾十種NoSQL技術。
大數據一體機
這是一種專為大數據的分析處理而設計的軟、硬體結合的產品。它由一組內建的伺服器、存放裝置、作業系統、資料庫管理系統,以及為資料查詢、處理、分析而預先安裝和優化的軟體組成,具有良好的穩定性和縱向擴展性。
四、大數據分析挖掘
從資料視覺化分析、資料採擷演算法、預測性分析、語義引擎、資料品質管理等方面,對雜亂無章的資料,進行萃取、提煉和分析的過程。
資料視覺化分析(AnalyticVisualizations)
資料視覺化分析,指借助圖形化手段,清晰並有效傳達與溝通資訊的分析手段。主要應用于海量資料關聯分析,即借助視覺化資料分析平臺,對分散異構資料進行關聯分析,並做出完整分析圖表的過程。具有簡單明瞭、清晰直觀、易於接受的特點。
資料的視覺化分析在資料分析軟體中是最為基本的一個要求,不管是資料分析專家來說,還對對普通使用者來說,都是如此。視覺化就是更為直觀的展現資料,並且讓資料自己說話,讓資料告訴觀眾結果。

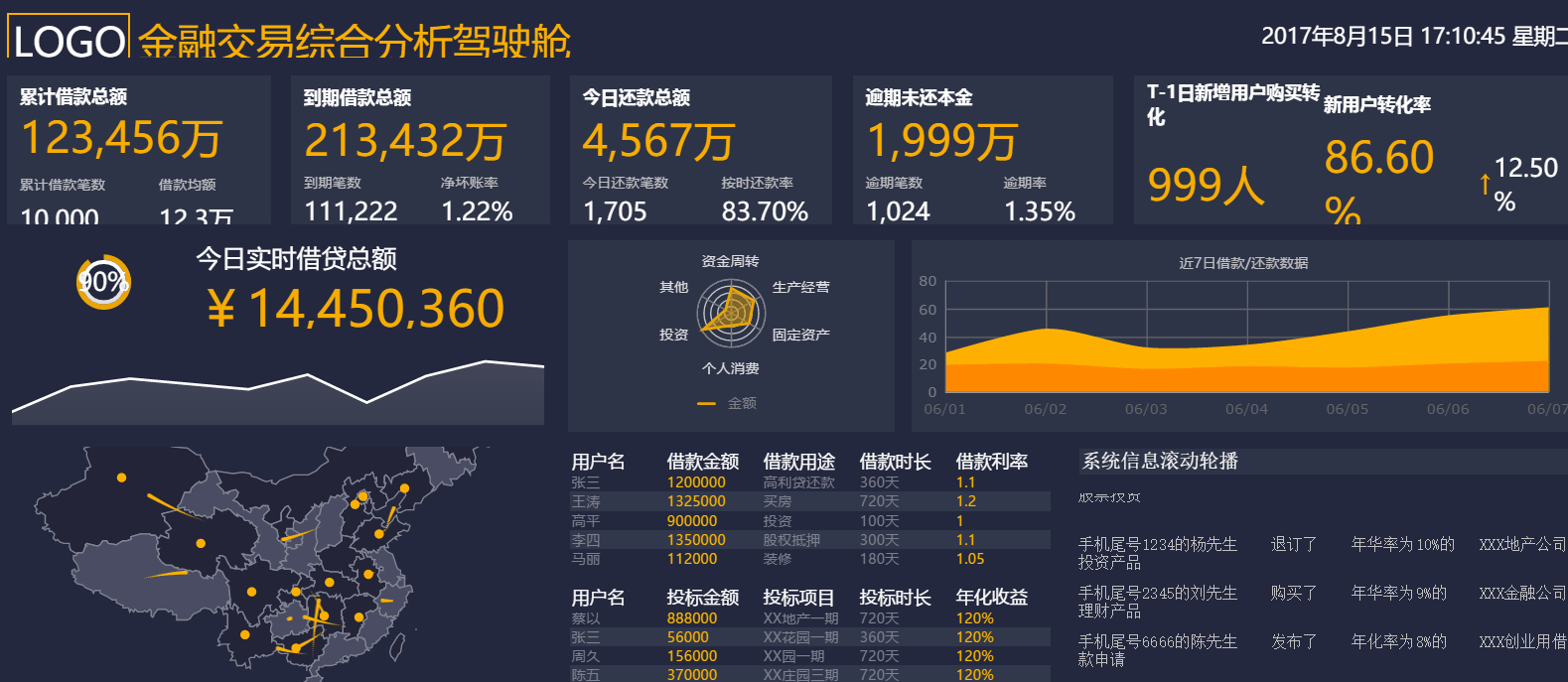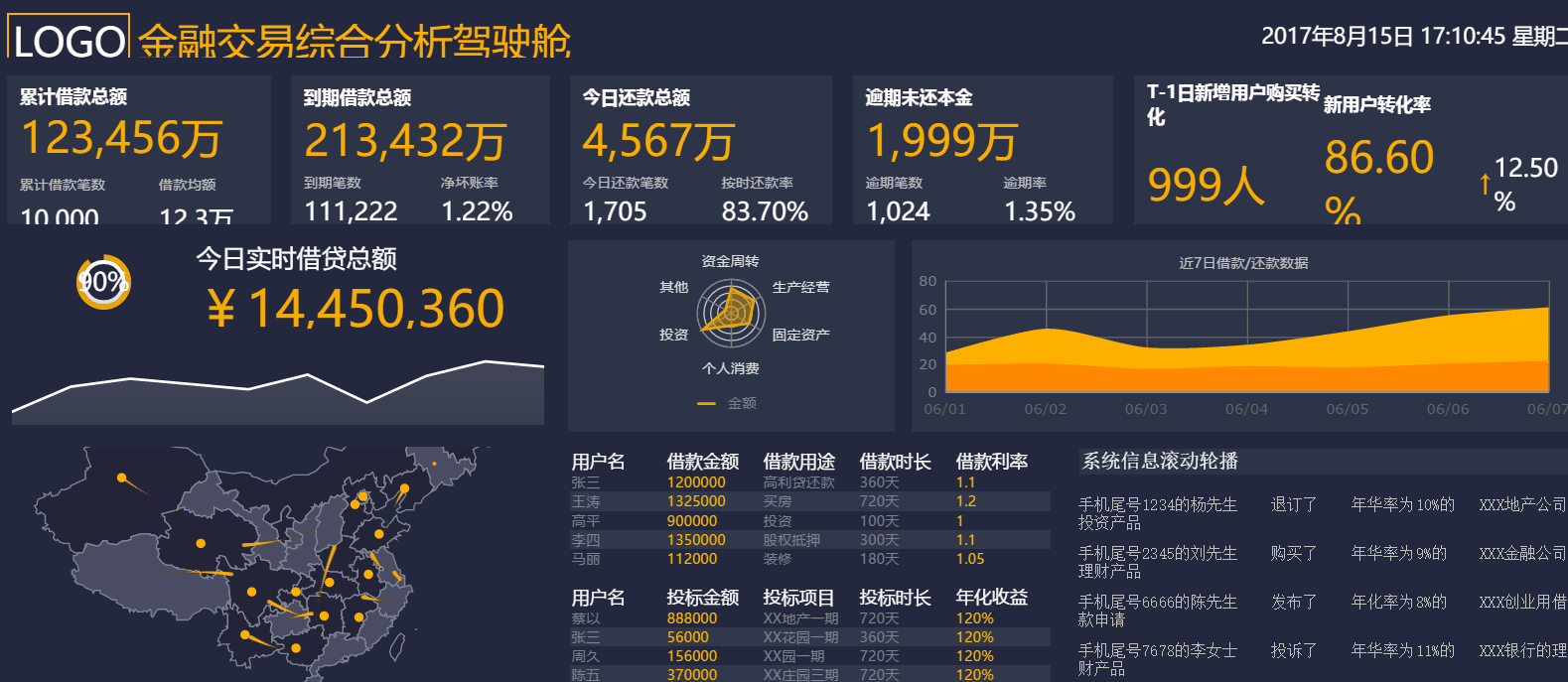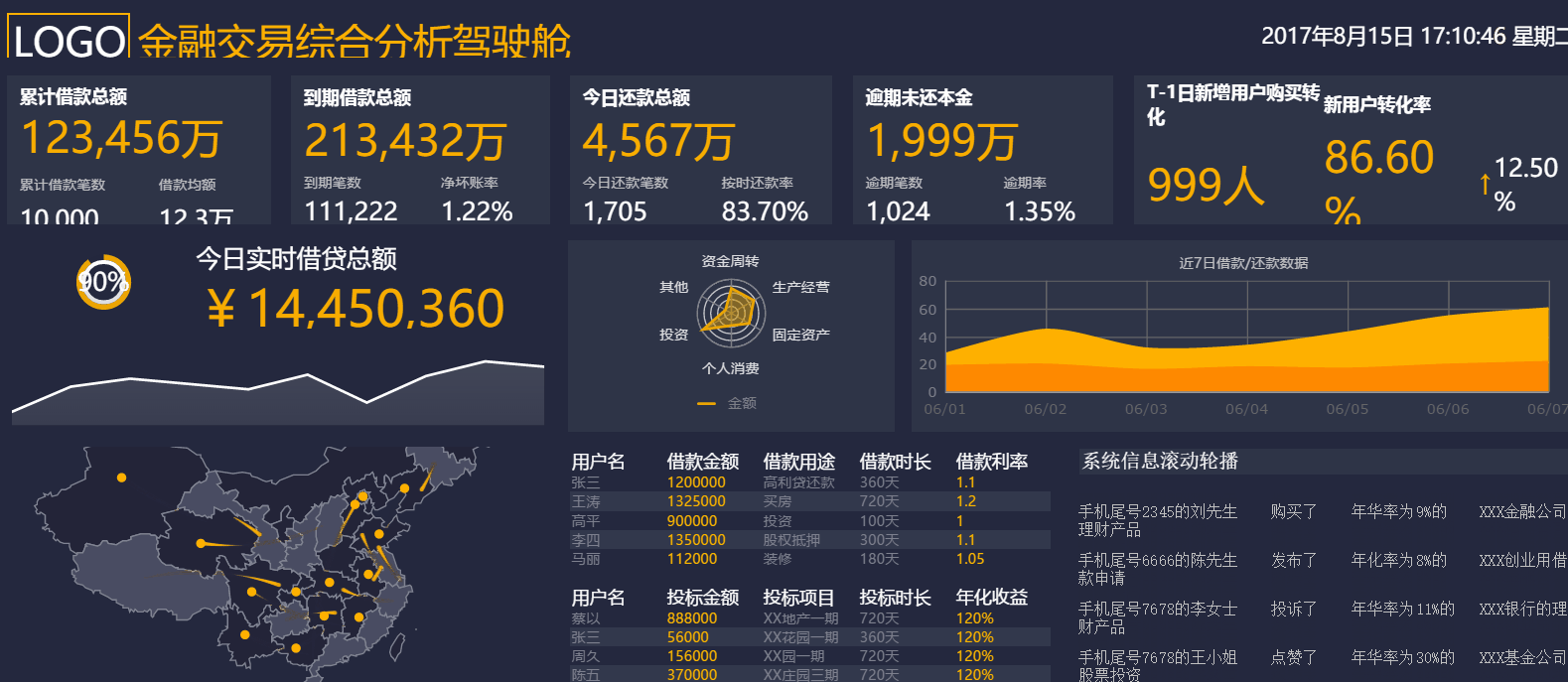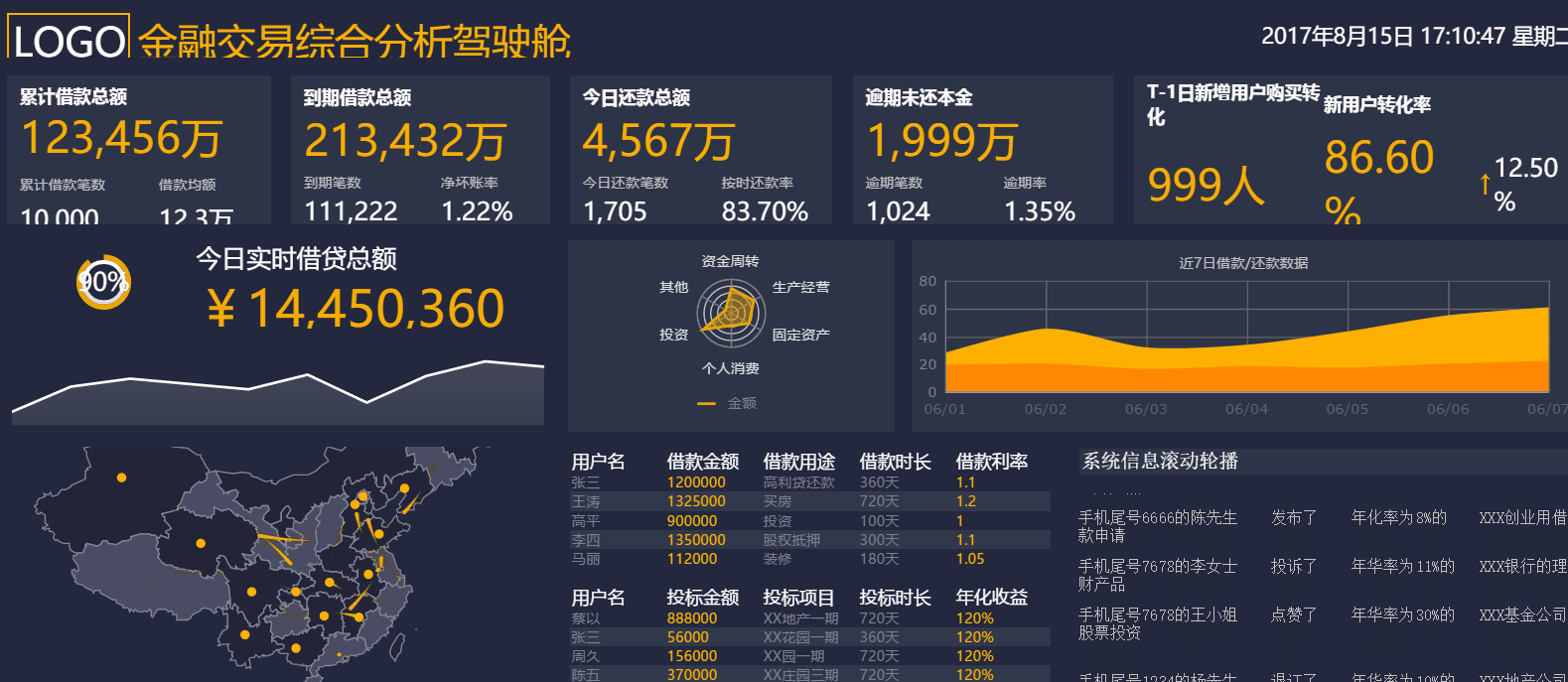
使用FineReport進行資料視覺化分析非常簡單,經過簡單的配置,使用者只需在B/S端簡單拖拽目標資料及相關維度,即可得到從不同維度分析的結果,提升資料視覺化程度,説明決策層做出準確的決策。同時降低了系統開發的定制化程度,極大地降低了系統開發者的維護成本。
資料採擷演算法(DataMiningAlgorithms)
資料採擷演算法,即透過創建資料採擷模型,而對資料進行試探和計算的,資料分析手段。它是大資料分析的理論核心。
資料採擷演算法多種多樣,且不同演算法因基於不同的資料類型和格式,會呈現出不同的資料特點。但一般來講,創建模型的過程卻是相似的,即首先分析使用者提供的資料,然後針對特定類型的模式和趨勢進行查找,並用分析結果定義創建挖掘模型的最佳引數,並將這些引數應用於整個資料集,以提取可行模式和詳細統計資訊。
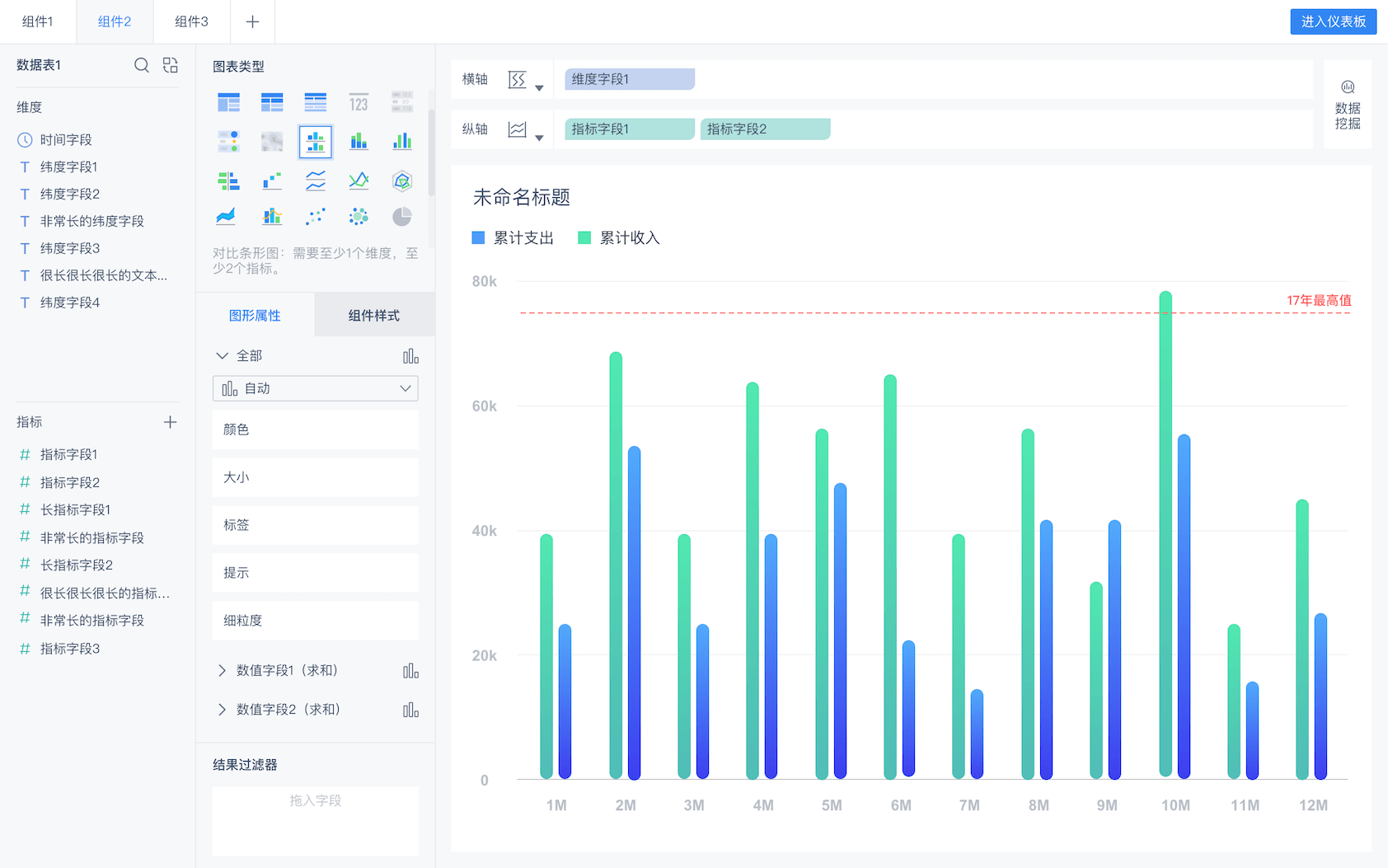
From FineBI
預測性分析(PredictiveAnalyticCapabilities)
預測性分析,是大數據分析最重要的應用領域之一,透過結合多種高級分析功能(特別統計分析、預測建模、資料採擷、文本分析、實體分析、優化、即時評分、機器學習等),達到預測不確定事件的目的。説明分使用者析結構化和非結構化資料中的趨勢、模式和關係,並運用這些指標來預測將來事件,為採取措施提供依據。如果資料分析軟體對資料採擷的好,那麼分析員就能在此基礎上對資料有更好的理解,而預測性分析則可以讓分析員在觀察資料分時通過視覺化的分析以及資料得到的結果更加有用,並且能獲得一些預測性的判斷。
語義引擎(SemanticEngines)
語義引擎,指透過為已有資料添加語義的操作,提高使用者互聯網搜尋體驗。目前非結構化的資料的多樣性給資料分析帶來了新的挑戰,而大眾也需要一系列的相關工具去對資料進行解析、提取和分析,而語義引擎就是當前一種能從【檔案】中只能提取出資訊的基本方法。
資料品質管理(DataQualityandMasterDataManagement)
指對資料全生命週期的每個階段(計畫、獲取、存儲、共用、維護、應用、消亡等)中可能引發的各類資料品質問題,進行識別、度量、監控、預警等操作,以提高資料品質的一系列管理活動。
以上是從大的方面來講,具體來說大數據的框架技術有很多,這裡列舉其中一些:
檔存儲:Hadoop HDFS、Tachyon、KFS
離線計算:Hadoop MapReduce、Spark
流式、即時計算:Storm、Spark Streaming、S4、Heron
K-V、NOSQL資料庫:HBase、Redis、MongoDB
資源管理:YARN、Mesos
日誌收集:Flume、Scribe、Logstash、Kibana
消息系統:Kafka、StormMQ、ZeroMQ、RabbitMQ
查詢分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分散式協調服務:Zookeeper
集群管理與監控:Ambari、Ganglia、Nagios、Cloudera Manager
資料採擷、機器學習:Mahout、Spark MLLib
資料同步:Sqoop
任務調度:Oozie
感謝閲讀!FineReport提供最全免費功能版本,不用等待,直接點擊以下按鈕激活&下載!
免費試用FineReport10.0>
獲得帆軟最新動態:數據分析,報表實例,專業的人都在這裡!加入FineReport臉書粉絲團!
相關文章:
資料探勘、視覺化ETL、大數據大並發……這才是企業需要的BI工具!
喜歡這篇文章嗎?歡迎分享按讚,給予我們支持和鼓勵!