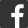觀光業一直是台灣引以為豪的產業,秀美的山水海景以及有溫度的服務吸引著世界各地的旅客前來。根據交通部觀光局的最新資料,我們做了一張2018年上半年台灣旅客出入境的狀況的儀表板。 來台旅客增幅3.7%,有望打破增長停滯狀態 2018年入境旅客人數為531萬5,879人次,與2017年同期的512萬3,868人次相比增長了3.7%。相比於2017年全年0.46%的幾近停滯的增長率來說,給了我們一個很大的希望。 上方地圖展示的是6月份臺灣旅客出境狀況,您可根據需要展示入境旅客的狀況 來台旅客的4大來源地不變,但大陸、日本有增長,港澳、韓國在下降。 大陸、日本、港澳、韓國仍然是旅客的四大來源地,但是相比於2017年同期,大陸來台旅客成長率最大,高達3.85%,日本增長1.59%,港澳和韓國分別下降6.11%和4.15%。 上圖是上半年來台旅客居住地累計圖 出境旅客持續增長,是入境旅客的近1.6倍。 出境游越來越夯,2018年上半年台灣出境旅客數為838萬2,451人次,與2017年同期的774萬9,700人次相比增長了8.2%,一直保持著穩步的增長。出入境旅客人次差距進一步拉大,相比於2017年的1.46倍和2016年的1.36倍,今年上半年出境旅客人次達到入境旅客的1.58倍之多。 出境旅客目的地變化不大,美國超越澳門進前五。 與入境旅客來源國相同的是,日本、大陸、港澳、韓國也是出境旅客的四大目的地。相比於2017年資料,美國從第6位上升為第5,超越澳門。 上述報表在FineReport報表BI軟體中製作,請在臉書相應貼文評論中留下+1,即可獲取報表數據與範本。
銷售預測對高效的銷售管理和業務資源配置至關重要。採購備料、安排生產、降低庫存、評估激勵銷售團隊、制定市場行銷策略甚至人事招聘都需要精準的銷售預測,預測的精準度對上市公司股價而言,更是不能有絲毫含糊。 在全員數據化精細化管理的大背景下,業務員、業務經理、銷售總監、CEO 都會面臨著制定銷售目標和銷售指標的問題,IT資訊部門也面對著為精準銷售預測提供數據和技術支援的問題。 既然銷售的預測這麼重要,有哪些簡單易用的方法可以幫助我們呢?今天來為大家介紹。 一、基值預測法——季節性變化分析 基值 = 每個月的實際銷售額 / 當年每月的平均銷售額。它反應了銷售的季節性因素,在進行銷售計劃制訂的時候,通過往年資料來判斷產品的季節性變動情況,新一年的年度計劃中不同季度的目標要把這個因素考慮在內。 比如基於上面圖片中的數據分析能夠得到哪些結論? 可能結論: 1、春節前的一個月是銷售旺季,問題:春節當月是淡季嗎? 2、3月、4月、5月,與8月、9月、10月、11月、12月是兩波銷售旺季,必須抓住機會。 3、在這兩波銷售高峰中,主要的拉動因素是什麼?–節假日集中。 二、加權移動平均法——趨勢預測分析 加權移動平均法是指,在「歷史重演」的慣性假設條件下,基於外部數據分析對未來做出估計,根據同一個移動段內不同時間的數據對預測值的影響程度,分別給予不同的權數,然後再進行平均移動以預測未來值。在運用加權移動平均法時,權重的選擇是一個應該注意的問題,一般而言,最近期的數據最能預示未來的情況,因而權重應大些。例如,根據前一個月的銷售情況,比根據前幾個月的數據能更好的估測下個月的銷售情況。但是,如果數據是季節性的,則權重也應是季節性的,例如,不能以1月份保健品的銷量來預測春季的銷量。 此法適用範圍: 1、當數據包含季節、周期變動時,移動平均的間隔數與季節、周期變動長度一致,才能消除其季節或周期變動的影響。 2、加權移動平均法並不能總是很好的反映出趨勢。由於是平均值,預測值總是停留在過去的水平上而無法預計會導致將來更高或更低的波動。 不適用範圍: 1、時間序列存在比較明顯的季節性趨勢時,不適於使用加權移動平均法。 2、時間序列存在比較明顯的發展趨勢時,不適於使用加權移動平均法。 3、加權移動平均法分析需要有大量的歷史數據才可以進行。 關於加權移動平均數演算法網路上有很多介紹和案例,適合使用這一方法的可以去搜尋一下套用。 三、滾動預測法——近細遠粗的定制計劃 按照”近細遠粗”的原則,根據上一期的預算完成情況,調整和具體編製下一期預算,並將編製預算的時期逐期連續滾動向前推移,使預算總是保持一定的時間幅度。滾動預算的編製,可採用長計劃,短安排的方式進行,即在編製預算時,可先按年度分季,並將其中第一季度按月劃分,編製各月的詳細預算。其他三個季度的預算可以粗一些,只列各季總數,到第一季度結束前,再將第二季度的預算按月細分,第三、四季度及下年度第一季度只列各季總數,依此類推,使預算不斷地滾動下去。 四、銷售漏斗預測方式 通過銷售漏斗完成加權預測,是最常見的銷售預測方式。銷售漏斗中每個銷售階段都有對應的金額和贏率,兩個數值相乘即該銷售階段可能漏下來的金額,最後匯總每個銷售階段的數值總和,即整個銷售漏斗的加權目標值。 經過計算,上圖中銷售漏斗的加權目標值是1200萬,也就是說,預計該銷售漏斗能夠做到1200萬的訂單金額。如果本季度業績目標是1000萬,銷售周期較短的話,基本可以判斷形勢一片大好。不過如果你的產品的銷售周期超過了3個月(超過一個季度時間),為了確保萬無一失,你還需要更多的客戶補充進去你的銷售漏斗。 通過銷售漏斗推測銷售目標值有一個「國際慣例」:銷售漏斗的總額應該3倍於銷售目標,經過大量銷售實踐總結出來的。這是第二種預測方式——靠經驗值預測。如果你要實現1000萬的銷售目標,你銷售漏斗的金額至少要保證有3000萬。這是銷售管理界最簡單粗暴的銷售預測方式。 五、承諾預測法 外企常用的預測機制——承諾預測。經驗豐富的銷售人員全面衡量打單因素後,對有些客戶十分有把握「拿下」,儘管這些客戶目前停留在初步接洽階段,贏率僅為10%。 比如,季度初銷售經理會和老闆承諾,銷售漏斗里有600萬的單子是100%能夠拿下來的,若這些情況不考慮在銷售預測的範圍中,則也會影響銷售預測的精準度。 然而,許多銷售經理或企業高層都很困惑,公司有了一套自己的銷售漏斗和銷售階段,在溝通和管理過程中,為何狀況頻出?有哪些因素影響了銷售預測準確性? 首先,銷售團隊缺乏統一標準和共同作戰語言。 在銷售經理給銷售過單時,對項目完成情況意見不統一是經常出現的情況。比如,銷售認為我和A客戶關係非常好,項目贏率已經到了80%,而項目經理仔細研究後發現,該項目的關鍵決策人都未覆蓋,根據其經驗估算贏率應該不足30%……若無統一的共同作戰語言和標準,銷售預測的準確性無從談起。 其次,銷售私心作祟,加劇預測困難。 一些銷售人員為了減輕壓力,對項目完成情況進行瞞報,以躲避老闆的追問和指責。還有一些銷售私心作祟,將一些訂單不上報,在主管季度末像無頭蒼蠅似的「湊」業績的時候,「拿」出來,充當「英雄」…… 那麼如何避免上述問題,實現精準的銷售預測?那就要搭建精細化的銷售流程。 簡言之,精細化的銷售流程不是簡單的銷售漏斗的幾個階段,而每個流程階段都要確定需要完成的具體步驟,同時明確銷售完成這些步驟所需要的銷售技巧和銷售工具,包括確定每個階段的產出物以保證每個流程階段的完成。這保證團隊有共同的銷售作戰語言。 在銷售流程體系中,只有當銷售了解客戶目標和痛點,並已經找到客戶支持者並贏得該支持者的認可,贏率才能達到30%。因此,在與銷售過單的時候,要檢查各個階段的產出物。如果銷售說其贏率已達30%,要學會通過銷售漏斗看項目的決策人是誰?銷售是否發給客戶demo演示的郵件?是否有與決策人溝通的郵件和反饋等,如果沒有這些,則可以開始懷疑這個單子是否真的達到了30%…… 這樣系統、標準的銷售流程的搭建,從銷售到高層領導者對銷售階段和贏率都有一個清晰地認知,在共同的銷售語言下,實現精準的銷售預測變得容易很多。 六、實驗行銷測試法 我們常常會遇到新產品的問題,沒有歷史資料分析可供參照。這時我們需要先在選定的幾個市場裡試推產品,得出一部分資料,再利用資料結果估計總銷量狀況,市場的選擇要則要考慮之前產品的銷售狀況,做到能代表整體情況,不會過於樂觀或悲觀。
無論你是剛開始從事資料科學,還是準備獲得資料科學或商業分析的學位,都需要學習更多內容。我們為學習者收集了2018年網路上的頂級資料科學資源。希望能夠幫助到你! 線上課程 1、Dataquest: https://www.dataquest.io/home 對資料科學家,資料分析師或資料工程師的感興趣的人可以在互動式編碼挑戰中學習,在真實的問題和資料科學項目中獲得成長。 2、Udemy: https://www.udemy.com 被稱為世界上最大的線上學習平台,目前擁有8000多個線上課程。他們的資料科學涵蓋從機器學習到資料可視化再到Python編程的所有內容。 3、Coursera: https://www.coursera.org/browse/data-science?languages=en Coursera與世界各地的大學和機構合作,提供線上課程。註冊人可以訪問錄製的視頻講座,自動評分和同行評審作業以及社區討論論壇,並且可以獲取一張電子課程證書。 4、DataCamp: https://www.datacamp.com 對於希望提高技能的初學者和經驗豐富的專家來說,這個網站是一個很好的資源。 DataCamp擁有與資料科學,統計學和機器學習相關的互動式R和Python課程。 5、Udacity: https://www.udacity.com/course/data-analyst-nanodegree–nd002 使用Python,SQL和統計數據來發深入洞察真相,傳達重要發現並創建數據驅動的解決方案,成為真正的資料分析師。 6、EdX: https://www.edx.org/learn/data-science 該網站提供免費的在線資料科學課程,以培養資料分析技能、提升知識水平。通過edX上的頂尖大學和全球合作夥伴的課程學習資料科學,統計和商業智慧。 7、Cognitive Class: https://cognitiveclass.ai 學習資料科學,人工智慧,大數據和區塊鏈的技能。Cognitive Class還為國際用戶提供日語,西班牙語和俄語課程。免費學習。 8、Springboard: https://www.springboard.com/workshops/data-science-career-track?afmc=2h 掌握資料科學的基礎並選擇您的重點領域:高級機器學習,自然語言處理或深度學習。提供真實項目練習來向僱主展示技能,提供個性化的職業指導和獨家招聘網站。 9、Data School(YouTube): https://www.youtube.com/user/dataschool/featured 此YouTube頻道屬於Kevin Markham,一位位於華盛頓特區的全職資料科學教育工作者。他的視頻涵蓋了一系列資料科學主題,如使用開源工具,Python和R等等。目前有6萬多訂閱者,免費觀看。 10、Siraj Raval(YouTube): https://www.youtube.com/channel/UCWN3xxRkmTPmbKwht9FuE5A/featured Siraj Raval的YouTube頻道提供視頻,鼓勵和教育開發人員構建人工智慧。他創建了引人入勝的視頻,教導觀眾如何使用AI製作遊戲,音樂,聊天機器人,藝術等。目前有40多萬訂閱者,免費觀看。 11、IntelliPaat: https://intellipaat.com/tutorials/ IntelliPaat教程涵蓋大數據,商業智慧和資料庫等主題。您可以向行業專家學習,並在成功完成課程後獲得認證。 12、Lynda: https://www.lynda.com/search?q=data+science 可以按照基礎、進階、高階水平選擇課程,內容涵蓋大數據、商業智慧、資料分析、資料庫、程式語言等。 13、Kaggle: https://www.kaggle.com/learn/overview Kaggle非常適合初學者。您可以選擇Python、機器學習、Pandas、數據可視化、R、SQL或深度學習這些課程。 資料科學博客 資料科學的博客內容多是英文,不熟悉使用的可以應用chrome瀏覽器的google翻譯外掛程式,一鍵翻譯閱讀。長期來看還是要掌握好英文這門技能。 1、Edwin Chen的博客: http://blog.echen.me Edwin曾在麻省理工學院學習數學與語言學,從業背景包括MRS的語音識別,Clarium的量化交易,Twitter廣告,Dropbox分析,Google資料科學。他的博客中提供有關AI人工智慧,人工計算和數據的相關文章。 2、DataScience.com: […]
近日DB-Engines發佈了全球資料庫8月排行榜,Oracle、Mysql、Microsoft Sql Server組成的第一梯隊,在經歷上月排名的暴跌之後,均強勢上升。其中Oracle的表現最為突出,在經歷了上次排名的下跌之後,本次迎來榜單最大漲幅,評分上漲34.24。 三大巨頭雖然將其他對手甩的很遠,但近兩年的趨勢來看,仍然不可逆轉的走下坡,Microsoft Sql Server相比於去年同期,更是下降152.82之多。這次三巨頭的排名月度上升,不知能否成為逆轉趨勢的拐點。 關於Oracle的強勢上漲,業界分析認為是受益於7月23日Oracle 18c的公眾版的發布。這個版本18.3是Oracle在2017年宣佈更改版本發佈計劃以來的第一個年度發佈版本。2017年7 月,Oracle決定對資料庫軟體版本發行策略進行重大調整,改為每年發行一個大版本,目的是讓使用者每年都能獲得最新的資料庫功能特性。年初Oracle就公佈了18C的文檔,一直以來否備受關注,這次7月更新想必會掀起一個小高潮。 Oracle資料庫18.3官方下載地址: http://www.oracle.com/technetwork/database/enterprise-edition/downloads/index.html 8月資料庫排名中還有一個非常搶眼的選手是PostgreSQL,相比上月和去年同期一直保持較快的增幅,已穩妥的成為資料庫第二梯隊的領頭羊。 在2016年末和2017年初和MongoDB短暫交手之後,一路高歌猛進拔得頭籌,不斷擴大和MongoDB之間的差距。作為開源資料庫的TOP2,按照這個趨勢發展下去,未來衝擊MySQL資料庫地位的可能性不是沒有。 查看完整榜單:https://db-engines.com/en/ranking DB-Engines資料庫榜單排名的依據: Google,Bing和Yandex搜索引擎查詢中的結果數量 Google趨勢中的搜索頻率 Stack Overflow和DBA Stack Exchange上的相關問題數量和感興趣的用戶數量 Indeed and Simply Hired 中的工作職位數量 LinkedIn and Upwork中的提及數量 Twitter中的推文的數量 您還可以參考《零基礎快速自學SQL,1天足矣!》
為什麼報表對ERP系統如此重要? 眾所周知,一到月末、季度末或年末時,各職能部門、各管理會議、各管理決策等都在為報表絞盡腦汁、加班加點和操心操勞。 事實上絕大多數中小企業所使用的國外ERP軟體,比如QAD Mfg/Pro,Exact,Movex,Adonix等,其設計目的只是供企業分銷製造以及財務日常交易錄入之所用,同時僅提供一些滿足基本需求的報表功能。 這一點與我們熟悉的財務會計軟體比如鼎新、正航、凌越等有很大不同。但後者僅僅以財務系統見長而不具備完善的流程控制,故不能算真正意義上的ERP系統。 即使大型的ERP系統也紛紛併購頂尖的商業智慧工具以擴展其產品的報表能力,比如前面完成的一系列併購:SAP收購BO(水晶報表),Oracle收購Hyperion,IBM收購cognos。 所有這些現象揭示了報表工具對於一個ERP系統的不可缺乏性,這也很好地解釋為何我們系統里有那麼多的客戶化報表。報表不僅供管理者決策分析之用,也能指導用戶正常地操作系統,比如下達一個訂單。 可以說,報表工具為ERP系統打開了一扇窗! 同一個類別的報表Inventory,如庫齡資料分析報表對於不同職能部門需求不一樣。 對於財務部門,需要數量,成本和金額等資料;而對於倉儲部門僅需要數量即可。對於可能從中推算出成本、價格等敏感資料,某些報表中需要將產成品描述等欄位屏蔽。 隨著業務的發展以及對於內控要求的不斷增加,我們仍然日益面臨著增長的定製化報表需求。 為什麼不直接對ERP二次開發? 1. 系統維護和版本管理不希望系統有太多的個性化,同時也不利於升級和標準化; 2. 由於技術和業務壁壘,一些標準模板的更改難以由某個人獨立完成; 3. IT資源緊張,難以得到及時更新,也缺乏人力運維。 為什麼必須標配報表工具? 布署一款實時性的本地報表工具不光對IT,對於最終用戶也有很大的幫助。它能夠讓我們從客戶化程式碼編寫的低效繁瑣中解脫出來,將自已的精力集中在理解用戶需求並幫用戶設計業務模型上面。 報表工具的License遠比ERP的要便宜。 對於某些僅從事查詢或報表的用戶比如一些管理人員,完全可以做為ERP系統帳戶的替代。 圖形化、可視化的界面為大多數用戶所喜愛。 目前,大多數報表工具支援各種各樣的資料庫,在他上面的投資和積累的經驗完全可以移植和擴展到以後的SAP甚至其它一些可能出現的系統上面,比如客戶關係客理、工作流等系統上。 更重要的是,由於商業機密泄露給競爭對手而帶來的一次性損失、或者我們為了加強商業密秘保護所做出的其它努力,可能也遠大於布署報表工具所需要的投資。 報表工具不失為企業數據化經營的最佳開端 現在很多企業都逐漸有了數據分析的意識。商品部說我要看門店銷售額分布,金融部說我要看投資轉化分析,老闆要看綜合指標統計、部門業績拆分、產品分析、用戶分析…… 但凡一個有點規模的企業,都有大量的數據躺在系統里,報表在Excel中。越來越多的業務分析需求,也暴露了各種數據收集麻煩,系統數據不能打通的問題。 報表BI平台可以把數據分析給統一管理起來,一方面減輕各業務人員做Excel的壓力,畢竟是誰都不想在做報表上花太多時間;另一方面,報表體系的規範倒逼數據的收集、數據的質量、經營分析體系的完善。 那麼,應該選擇什麼樣的報表工具? 幾個參考標準: 是否支援所需的數據源,有沒有開放介面 數據填報手機、報表分發等功能,都是常用的需求 報表製作是否簡單,做表的效率高不高 數據安全、許可權管理——保證資料安全 如果選擇開源工具,得保證有專人運維 市面上的工具大家可以對比價,各家官網技術參數和功能都很透明。 最終選擇FineReport報表BI軟體的理由: 報表開發簡單速度快,2個人一年可以完成集團120多張報表的開發。 搭建統一的數據管理平台,取數、分析一脈相承,讓數據更好的用於業務經營和決策。 可以快速開發報表,可以和OA、ERP、MIS、CRM、TMS、WMS、BPM、EHR、考勤等系統的無縫集成。 感謝閲讀!FineReport提供最全免費功能版本,不用等待,直接點擊以下按鈕激活&下載! 免費試用FineReport10.0>
作者:燕飛 Kyligence 大數據老司機,擁有超過15年的大數據/資料倉儲領域從業經驗,對大數據/資料倉儲的建設規劃、架構設計、技術體系、方法論及主流廠商的產品和解決方案,均有深入的研究和實踐。 【開胃菜】 十五年前,剛開始工作,從帝都回老家。 某長輩和藹的問我:「工作了啊,做什麼的?」 我躊躇半天答曰:「挨踢(IT)。」 長輩不假思索的來了一句:「哦,在中關村賣光碟啊!」 我……我…..我……(叔叔,你知道的太多了) 【副菜】 五年前,一夜之間,「大數據」一詞開始紅遍大江南北,再碰到別人問我時,我終於可以用一個網紅詞來輕鬆回答:「做大數據的!」 (感謝行动動网路的發展,感謝各大IT廠商的炒作,感謝國家的重視和規劃,感謝所有TV和AV) 但就在上個周末,跟老媽電話聊家常時,她突然很好學地問了我一個很有深度的問題: 「我知道你是做大數據的,但你們大數據到底都在做些什麼?」 我一時詞窮,不知道該從何說起。而類似的問題在知乎上也經常被一些即將面臨就業、被「大數據」三個字圈粉、希望成為資料人的莘莘學子們所追問,因為人懶,基本上都沒有好好回答過。 於是,為了給普及「大數據」貢獻點綿薄之力,為了讓邊緣人士們對大數據多一點基本理解,也是為了能回答老媽的問題,我決定寫篇文章(省點電話費)來介紹一下大數據以及資料人的日常工作。 大數據雖然已經是大家耳熟能詳的熱詞,但資料領域裡的許多術語和概念仍然會讓人不明就裡,所以我準備從「做飯」這個普通人應該都有基本了解,老媽更是熟稔於心的領域來切入。 【主菜】 正所謂「巧婦難為無米之炊」,做飯首先得有食材,大數據也一樣,沒有資料說什麼都是扯淡,所以資料就是資料人的食材(只要有資料,我不用吃飯)。 做飯通常都要包括「買菜~洗菜~配菜~炒菜」這幾個必需環節,無論你是開飯店還是家裡一日三餐,做飯的規模大小會有不同,但流程卻是一樣的。而這幾個環節其實正好對應了資料人的日常工作內容:買菜(資料採集)~洗菜(資料清理)~配菜(資料建模)~炒菜(資料加工)。 1、買菜(資料採集) 買菜,出門首先要考慮去哪裡買,到地之後溜達溜達看看買什麼食材,看中一個之後討價、還價、交錢,肉、蛋、青菜,各種要買的食材都得按這個流程來一遍,買齊之後就走人回家了。 對於資料人來說,我們把這個買菜的過程叫做資料採集。 菜市場就是我們通常所說的資料源。 買菜的選擇很多:超市(種類較少,質量上乘),農貿市場(種類較多,菜品一般),露天早市(啥都可能有,運氣好還能吃到野味)。 資料源其實也一樣,資料庫(超市)中储存了結構化的業務資料、交易資料,感測器(農貿市場)產生大量半結構化日誌資料、機器資料,網路上(早市)充斥著各種參差不齊的非結構化資料。 到了菜市場我們得選菜,所有的食材我都想吃,但錢永遠是不夠的,所以我只能有選擇性的買,這個過程叫資料調研,哪些資料是有用的,哪些資料用得起,得有個篩選。 溜達了一圈,確定要買豬肉、雞蛋和黃瓜,得跟賣家挑肥揀瘦、討價還價、敲定斤兩,這個過程叫資料介面規範。 費勁口舌,勞心勞力把菜買齊之後提菜回家,這個過程叫資料傳輸。 根據買菜方式、習慣的的不一樣,資料採集還可以細分出很多類型: 肉類保質期長,一次買一周的量,可以叫全量採集。 青菜講究新鮮,每次只買當天的菜,可以叫增量採集。 每天早上都得去買菜的,可以叫批量採集。 賣家每次上了新菜都主動給你往家送的(土豪專用),可以叫流式採集。 2、洗菜(資料清理) 洗菜就很好理解了,無論哪裡來的食材,都多少存在衛生或者質量問題,買回來後都得洗乾淨、摘清楚才能吃,不然小則影響口感,大則損害健康。 資料也是一樣,拿回來之後得檢查一下,資料內容有沒有缺斤少兩,資料值里有沒有爛菜葉,不然後面的報表、資料分析出來的結果就全是錯誤結論了,我們把這個檢查、糾正資料本身錯誤的過程叫做資料清理。 由於數字世界裡各種資料源的多樣性、複雜度遠遠高於現實生活里的菜市場,資料清理流程需要面對和處理的問題也就遠遠多於洗菜,為了解決和防範資料產生、使用過程中出現的各方面問題,資料領域細分出了一個專門的研究方向叫資料治理,比如: 為了了解各個菜市場的情況,我們需要記錄每個菜市場、每個賣家的豬肉、雞蛋、黃瓜等各種食材的大小、顏色、價格等特點,這個叫元資料管理。 記錄完之後發現每家的特點都不一樣,完全沒有可比性,於是我們決定對豬肉、雞蛋、黃瓜的大小、顏色、價格進行統一規定、統一定價,這個叫資料標準管理。 定完標準之後,我們得定期對各個菜市場進行檢查,看看他們有沒有按標準辦事,這個叫資料質量管理。 3、配菜(資料建模) 配菜指的是根據要炒什麼菜,將需要的各種食材事先搭配好放在一起,比如說我們要炒木須肉,那就把豬肉、雞蛋、黃瓜都洗凈、切好放在一個碗里,這樣在炒菜的時候可以手到擒來,無需到處找食材,能夠很好的提升炒菜的效率。 一般家庭做飯可能不會嚴格這麼做,但對於餐飲行業來說,這是必備環節,想想買回來一車的食材,洗凈、切好之後,如果沒有一定的擺放規律,不能充分保證大廚炒菜時的效率,客戶半天吃不到菜,那這個飯店的翻台率和回頭率絕對高不了,還是趁早關門大吉。(老媽是個統籌規劃能力很強的精細人,無論是宴請賓客還是一日三餐,都會在炒菜之前把各個菜所需要的食材進行事先搭配,所以讓我得以了解。) 而在資料工程里,也同樣有個專業性很強甚至被神話的配菜流程,這就是傳說中的資料建模。資料建模就是建立資料存放模型,把各個資料源過來的各種資料根據一定的業務規則或者應用需求對資料重新進行規劃、設計和整理。 配菜這個流程也許在做飯過程中不起眼,有時候可有可無,但是在資料工程里,資料建模卻是個非常關鍵的環節,所以多說兩句。 資料的種類之多、複雜度之高遠遠超過食材,比如一個銀行,內部和業務、流程、管理相關的IT系統一般都超過100個,這也就是100多個菜市場,而每個菜市場能夠提供的食材少則數百個,多則成千上萬個,這都放在一起就是幾十萬個食材,再加上外部更加複雜的其他資料源,這麼多不同類型、不同標準的食材放在一起,怎麼才能讓後面的炒菜更加高效和科學,其複雜度和可研究性也的確遠遠高於真正的配菜。 正因為如此,在資料發展史上出現了不少專業的建模(配菜)方法論: 比如說按食材種類進行擺放的(豬肉放一堆,雞蛋放一堆,黃瓜放一堆),我們叫範式建模,你要是開個火鍋店或者準備吃火鍋,那肯定是採用範式建模來配菜了 比如按菜品種類進行擺放的(炒木須肉的放一堆,炒宮保雞丁的放一堆),我們叫維度建模,你要是吃個家常炒菜,那採用維度建模方法來配菜就更合理了 各種方法論都有其產生背景、適用場景和支持者,為了不引起戰爭,這裡就不做深入討論了 在這些方法論基礎上,經過不斷的實踐和研究,一些領先的資料廠商推出了標準的行業資料模型,什麼叫行業資料模型呢,因為每個行業的業務特點不一樣,比如說銀行業、電信業、零售業的業務模式就有很大差異,資料也是不一樣的,所以不同行業的資料怎麼擺放,資料模型怎麼設計,有著很強的行業獨特性,所以每個行業都需要自己特定的資料模型,這叫術業有專攻。 上面這段話沒看懂?沒事。簡單來說,行業資料模型就是「飯店籌備攻略」。 比如說你覺得川菜很賺錢,想開個川菜館,但你只是個標準吃貨,只吃過豬肉沒看過豬跑,怎麼辦?沒事,我這有本「川菜開店籌備攻略」,裡面什麼都有: 首先,攻略里會告訴你川菜里有哪些知名、流行、暢銷的菜品(比如水煮肉、毛血旺等等),定期更新,圖文並茂,這樣菜單有了。 […]
文:黃進然 畢業於中山大學數學系,10年以上資料科學領域從業經驗,曾任職於順豐科技,目前在一家創業公司擔任資料負責人,從事零售行業資料應用研究,擅長資料分析、資料探勘、資料產品以及資料視覺化。 每年總有很多人,懷揣著對世界的一知半解、滿腔似火的熱情、還有對美好生活的嚮往,走出象牙塔,投身社會。 世界很大,誘惑很多。對於未來,甚至在工作多年後,他們仍然沒有清晰的方向,或者缺乏獨立、深度的思考。 方向很重要,而人生很短暫。往哪裡走,怎麼走,再怎麼也得花點時間思考一下,不是嗎? 如果你決心要在資料科學領域有所作為,或者立志做資料分析,這篇文章提了點小建議,希望對你有所幫助。 一、去大廠還是去小廠? 我們做每件事之前,都要先明確做這件事的目的和意義是什麼。 先來問問自己,做資料分析價值是什麼?我的理解是,致力於用資料幫助企業解決業務問題,輔助業務決策。 關於這個問題,你可以花3-5年時間來思考和領悟,不急,但需要想清楚。 你還面臨一個抉擇,到底是去大廠還是去小廠? 之前接到很多獵頭電話,不少都會問:「你是做分析還是做探勘的呀?」剛開始,也常會和獵頭在電話里「理論」一番。後來在大廠待過才明白,大廠分工比較細,分析是偏向經營分析,即取數分析寫報告,而探勘則是建模調參部署等。小廠就不一樣了,談需求、確定思路、指標設計、平台搭建、接入資料、處理資料、建立寬表、模型訓練、結果分析、撰寫報告、模型部署、報表計算、資料可視化等一整個流程,一個人幾乎都可能會參與。 如果有機會,請一定要去大廠歷練幾年!大廠大多都很開放,常常敢為天下先,敢於引入一些新的東西,包括技術、思維、制度,技術比較先進,優秀的人也很多。大廠的管理制度也很完善,福利待遇當然會更好些。大廠的資料規模絕對夠大,而且應用場景也多,可施展的空間應該會比較大。所以,抱著學習的態度在大廠里混幾年,是可以成長很快的。(有好,當然也有不好)大廠流程繁雜,整體效率偏低,提一個取數申請可能需要1-2周。大廠的內部競爭也大,存在於不同專案團隊,也存在於同一部門不同成員之間。大專案資源投入大,小專案資源申請很困難,重視程度也不一樣。最主要的,大廠分工很明細,不同職位的輪換似乎不大容易,從入職到幾年後離開一直做經營分析都是有可能的,容易導致能力的單一,不利於個人綜合素質的培養。 相比之下,小廠就靈活多了,人和事都不會很複雜,而且效率也高。小廠可能會優先考慮做這件事情的投入和產出,即看應用效果。(大廠反而願意給資源去試,短期內不怎麼關注投入產出。)所以,在小廠工作,既要學會幫公司賺錢,也要學會幫公司省錢。小廠分工不會很細,大多需要一個人做多種工作。所以,小廠裡面的程式設計師常常身懷多技。但小廠資料規模小,技術實力較弱,團隊成員整體素質不高,而且專案流程不大規範,常常怎麼簡單怎麼來,怎麼高效怎麼來。有些小公司的程式設計師,除了對外發過一兩封郵件,平時的溝通幾乎是在即時通訊里,結果待了幾年之後連寫一封郵件都不會。有些小廠自己沒有資料,重要是作為乙方給大企業做專案,這種模式常常受甲方牽制,可發揮的空間很小,而且一個專案周期往往比想像中要長(我本人之前就厭倦做乙方),因此不大建議去這樣的公司。 不管大廠還是小廠,在選擇時,建議都要看看所要加入的團隊。 綜合來說,建議先去大廠混幾年,再去小廠找個Title高點的職位發揮自己所長。 再來說幾句,什麼場景下分析,什麼場景下挖探勘呢? 分析其實是一個很籠統的概念。把當前營業額跟去年同期做對比發現增長了不少,這個也可以認為是分析。分析是從資料中發現問題或規律,並提出合理的建議。分析常常伴隨著要寫簡報,進而要給業務方彙報分析結果。最好是給決策層彙報,因為決策層有拍板的權力,而且對資料分析結果的感知和可能的應用有自己獨到的認知。 如果需要把分析的結果固化下來,定期輸出結果,提供給業務方,這個時候就需要開發資料產品了。 資料探勘是用演算法解決某個具體的複雜問題,用常規分析方法解決不了的,如客戶流失預警、商品最優推薦組合、最有投遞路線規劃等。 所以,我一般認為,分析是從資料中發現問題或規律,而探勘是其中的一塊。 二、1-3年,「所見即所得」,打磨基礎技術 在職業生涯的初期,請牢記,「所見即所得,所感即所知,多見即多得,多感即多知」。 不管在大廠還是在小廠,一定要參與到實際專案當中,好好打磨自己的技術。不管是大專案還是小專案,一定要藉助來之不易的機會,以極致的工匠精神修鍊自身。 你最好能從基礎資料處理做起。只有這樣,你才能早點知道,資料並不像在學校里做實驗用到的資料那樣「好」,它可能看起來「又臟又亂」。只有這樣,你才能早點知道,給你取數的那個程式設計師是如何花了2-3天甚至一周時間才把數算好。 如果你精通SQL,那就太好了,這樣就可以直接能夠在資料平台查看原始的資料了。 最好要看一看最原始的資料長什麼樣。你不一定能一下子理解這些資料,但你可以慢慢地感受它們,因為它們所投射出來的是最真實的業務場景。 舉個例子吧,原始的會員註冊資料裡面,性別一般填「男」、「男性」、「女」、「女性」、「未知」、「其它」等值,但處理好之後的二手資料裡面,性別就變成了「男」、「女」、「未知」等三個值了。僅看這三個值,可能會漏掉一些業務場景,填「男」可能是從行動端輸入時選擇的,填「男性」則可能是手工填寫註冊表格時勾選上的。而漏掉的這個場景,說不定就是所要找的那個分析點。 你最好還能熟練掌握一兩門編程語言,比如當下流行的Python,作為入行的基礎技能。(順便說一下,程式界普遍認為只會SQL的不算真正的程式設計師~~) 當今時代,編程已經從娃娃開始抓起。早在5年前,英國規定5歲以上兒童必須學習編程課,法國將編程列入初等教育選修課程,美國已有40個州制定政策支援計算機科學,有35個州將計算機科學課程納入高中畢業學分體系。美國前總統奧巴馬就曾在全美髮起「編程一小時」的運動,旨在讓全美小學生開始學習編程。編程將是一項很基礎的技能,也將是承接其他知識的基石。在未來,會編程很可能跟使用智慧手機一樣普遍。 當處理基礎資料的時候,必然會在資料庫或資料平台上進行。你可能需要對這些儲存資料的環境加以了解,如傳統的結構化資料庫Oracle、Mysql、DB2等,又如當下流行的Nosql資料庫HBase、Redis、MongoDB、Cassandra等,再如大數據集群平台、原理及其相關概念,類似Hadoop、Hive、Hue、MapReduce、Spark、Scala、Sqoop、Pig、Zookeeper、Flume、Oozie等。你或者也需要了解資料傳輸的工具,如DataStage、Kafka、Sqoop等。你甚至也可能被安排做安裝系統、部署軟體、配置環境、同步資料等一些瑣碎的工作。 關於這些,如果你非常感興趣,可以考慮往大數據平台方向發展,成為資料開發工程師、資料平台運維工程師、或者資料平台架構師。 你不必理解太深,可僅僅停留在了解層面,但知道這些知識會讓你和資料開發工程師、運維工程師和平台架構師溝通起來順暢很多。 當處理和分析資料時,有些關於資料的操作是必然需要掌握的。首先是常見格式的資料匯入匯出,如TXT、CSV、XLS,然後是主要的資料加工技巧,包括建表/視圖、插入、更新、查詢、並聯、串聯、匯總、排序、格式轉換、循環、常用的函數、描述統計量、變數,等等。 這些操作很基礎,但不簡單。你可能經常會遇到各種情況,如花了一個下午時間就是沒能把一個很小的CSV資料文件正確地導入到資料庫中,不是亂碼就是錯位,或者兩表關聯時老是報一些煩人的錯誤,或者日期欄位進行格式轉換時出現空值……反正狀況百出,防不勝防。 關於這些基礎操作,需要不斷積累經驗,盡量能夠做到在不同場景下快速高效地完成,輕鬆應付。 如果有人已經給你取好了數,而你的工作是分析資料寫報告,那麼分析技巧首先是你需要培養起來的。對拿到的資料,要時刻保持疑問,不能太樂觀,因為別人算好的資料未必完全是你想要的資料,又或者資料質量並不是你想的那樣好。 在分析之前,需要進行資料探索,看看資料質量如何。比如,你需要清楚有多少資料量,有什麼訊息,可衍生什麼指標,缺失情況如何,如何填補缺失值,值的分布情況如何,如何處理極值,名義/字元變數是否需要轉換,等等。 分析時,要清楚指標不同形態的含義,如絕對值、佔比、同比、趨勢、均值、標準差,等等。 在這裡,我想指出,資料有對比才有意義。如果一個窮人撿到500元,他會很高興,這夠他吃好幾天了。但如果讓一個富人去撿500元,那感覺就不一樣了,他可能覺得他不值得這麼做,因為用彎腰去撿的時間掙到的錢遠遠不止這麼多。 統計學知識是必須要掌握的,這是基礎。如果你非數學或統計學專業出身,那麼請自學。 另外,也請你一定要掌握主流演算法的原理,比如線性回歸、邏輯回歸、決策樹、神經網路、關聯分析、聚類、協同過濾、隨機森林,再深入一點,還可以掌握文本分析、深度學習、圖像識別等相關的演算法。 關於這些演算法,不僅需要了解其原理,你最好可以流暢地闡述出來,還需要你知曉其在各行業的一些應用場景。 關於這些演算法,你最好能夠參與關於模型開發的具體專案實踐。那樣的話,你就可以清楚關於建模的大概流程是怎麼樣的,不同演算法在建模中有不同,需要注意哪些地方。 如果你打字速度不快,那也最好重視起來,這雖然是一個不痛不癢的問題,但也在較大程度上影響你的工作效率,進而影響到你的工作產出,當然也可能因此會影響到你的薪資哦! 另外,還有一些提高工作效率的小技巧,也可以多學多掌握。例如,一些電腦的快捷鍵,定期儲存檔案,檔案的歸類存放和快速查找,等等。 作為職場新人,你不僅需要打磨技術,純技術之外的技能也需要不斷修鍊。 職場的做事方式方法、為人處事以及一些潛規則,更多時候只能靠悟,說出來就可能不大好了,因此需要不斷領悟。畢竟,悟性這東西是很重要的。 還有,溝通是程式設計師普遍的老大難問題,建議重視起來並加強。 你甚至可以學一下投影儀或印表機怎麼用。(說不定可以靠這個技能在老闆或同事前面大攢人品哦~~) 如果你有機會和很牛的人在一起工作,那你太幸運了。你可以多請教優秀的人一些問題,也可以平時多觀察那些優秀之人的做事方式、工作習慣,看看有哪些好的地方、好的品質值得你學習。只要吸納進來,就可以轉化為你的優點,推動你進步。 我畢業的第三年,看到俞敏洪老師在一些演講中提及他大學時讀了800多本書,很受觸動,真正認識到了讀書的重要性,於是給自己制定了一年讀50本書的計劃,什麼書都讀,三年左右時間,我的心智和心態都發生了很大的改變,完全不一樣了。 俗話說:「三人行,必有我師。」每個人都有每個人的優點,對於所遇到的每個人,建議多欣賞別人的優點,少抨擊別人的缺點,這樣你就可以「兼收並蓄」,逐步塑造更好的自己。 三、3-5年,「技多不壓身」,拓展能力邊界 當邁過了最初的3個年頭後,你的技術越來越好,也做了不少專案,也越來越清楚自己未來的方向,但你也會發現有越來越多的東西還需要去學習和加強。 […]
作者:燕飛 Kyligence 大數據老司機,擁有超過15年的大數據/資料倉儲領域從業經驗,對大數據/資料倉儲的建設規劃、架構設計、技術體系、方法論及主流廠商的產品和解決方案,均有深入的研究和實踐。 在之前的文章《講透大數據,我只需要一頓飯》里,我用做飯這件大家身邊的事情來介紹了大數據及資料分析工程,應該能夠讓大家對資料分析這件看上去很專業的行業有了一定的認識,很高興的是文章也得到了很多資料圈專業人士的共鳴和互動。 這篇文章我們會順著之前的思路,稍微深入一點,聊聊資料分析架構。 什麼叫資料分析架構,說的通俗點,其實就是資料採集(買菜)、資料建模(配菜)、資料加工(炒菜)、資料分析(吃菜)這些資料分析流程應該如何劃分功能模塊(專業化分工),才能方便靈活、規模化、最大化的滿足廣大數據消費者(吃貨)的資料分析(美食)需求。 就好比吃飯這件事,我們可以自己在廚房裡做,去飯店吃,或者叫外賣等不同方式,這幾種吃飯方式是人類生活方式的一種進化,更是通過不同的專業化分工滿足了吃貨們不同時期、不同層次的需求。 而資料分析作為一件相對來說比吃飯更專業的事情,也同樣需要通過流程設計和專業化分工來滿足更廣泛的資料消費需求,我們通常叫做架構設計。 閑話少說,先直接上圖,我把迄今為止的資料分析架構的歷史簡單分為三個階段: 資料分析1.0階段:業務報表 業務報表階段是資料分析的初始階段。隨著資料庫技術的出現,企業紛紛開始資訊化建設,業務流程資訊化沉澱了大量數字化的業務資料,而資料分析的需求其實大家一直都有,既然有了資料沉澱,通過這些資料進行報表統計和資料分析的需求自然就出現了。 1.0階段,資料分析開始萌芽,資料加工、報表統計都在業務系統里直接進行的(資料產生和資料分析都在同一個系統里進行,所以這個時候還沒有資料採集一說)。這就好比自己在家裡做飯吃,可以想像,由於食材(資料)、廚房(資料庫資源)、手藝(專業能力)等方面的限制,吃飯的體驗不會太好,主要滿足吃飽(報表統計)的需求。 當然現代業務報表有了很大的改變,比如帆軟finereport一類的報表製作工具,可以跨業務系統、跨資料庫取數做報表做分析,甚至對接資料超市、資料倉儲(接下來我正要說)。 finereport製作的dashboard 資料分析2.0階段:資料超市(Data Mart) 由於在業務系統里直接做資料分析體驗不好,還可能會影響正常的業務流程,而企業資料分析的需求越來越完善,業務人員自然而然的希望在業務系統之外專門搭建一個用於資料分析的獨立新系統,既能用於支持資料分析,又可以不影響正常的業務流程,於是,資料超市應運而生。 從資料超市開始,資料分析開始作為一個正式的行業出現,出現了從業務系統到資料超市的資料採集和傳輸(買菜)需求,另外,資料加工,資料分析等專業崗位和從業人員開始出現。 這就好比飯店的出現使得在吃飯這件事上出現了專業化分工,同時也開創了餐飲行業。飯店裡有人專門買菜,配菜,炒菜,大廚開始出現,這一方式很好的滿足了廣大吃貨在省事、美食選擇、口感方面的需求,體驗自然是棒棒的。 資料分析2.5階段:資料倉儲(Data Warehouse) 隨著企業資料分析活動如火如荼的開展,資料超市開始越建越多,同樣的資料加工邏輯、指標等難免在分散的資料超市裡被重複計算,浪費計算資源不說,經常就會出現資料統計口徑不一致的問題,讓管理者們不知道自己該相信哪個資料。 這就好比飯店開的多了,同樣的菜品在不同的飯店裡難免會雷同,也就是同一個「魚香肉絲」不同飯店做出來的的口味難免會不一樣,吃貨們肯定會迷惑哪家才是最正宗的,也希望知道哪個才是最好吃的。 這個時候,資料倉儲概念應運而生。 資料倉儲為了解決資料超市分散建設帶來的資料不一致、重複計算浪費資源等問題,提倡以一個集中式平台來統一進行資料採集、資料清理、資料加工,並且向外部提供各種資料分析產品和服務。 資料倉儲算是開創了資料分析史真正意義上的一個時代,對資料分析行業的發展和成熟有著不可磨滅的貢獻: 誕生了專門的資料倉儲技術(MPP,massively parallel processing)以及一大批相關的專業廠商,來解決大量資料需要集中進行存儲、加工和分析的技術難題 發展了體系化的資料倉儲系統建設方法論和最佳實踐 培養了一大批資料倉儲從業人員(DWer) 既然,資料倉儲時代在資料分析史上有著如此重要的地位,並且在今天仍然有著深遠的影響,那麼,問題來了。 為什麼資料倉儲階段只是2.5而不是3.0呢? 首先,從架構的角度來看,個人認為資料倉儲相對於資料超市並沒有本質的區別,這個從上面的「資料分析架構發展的三個階段」圖中也能看出來,資料超市和資料倉儲的架構是非常相似的,資料倉儲可以簡單的認為是一個超級資料超市,區別只在於規模,這就好比為了規範菜品質量,讓大家能夠一站式吃到各種五花八門的菜品,我們開了個超級大飯店,雖然這個飯店很大,但仍然是個飯店。 其次,資料倉儲以解決資料超市資料分散、資料口徑不統一為目標,提出了打造企業級統一業務視圖的願景(The single view of business ),其建設方法強調資料採集規範化,資料管理標準化以及資料加工流程化,這種建設思路從資料管理的角度來說是非常有價值的,產出了很多成熟的資料管理規範和資料治理方法論。 但……是…… 從資料分析的角度來看,雖然數倉系統的建設的確一定程度上滿足了業務部門的資料分析需求,然而,傳統資料倉儲建設方法在靈活的支援各種資料需求、敏捷的響應分析請求、普及企業資料驅動的分析文化方面,卻始終心有餘而力不足。 造成這種情況,雖然有著技術、成本方面的原因,但架構耦合性高、建設方法過於僵化也是重要原因,比如: 資料倉儲集中式的平台架構方式,將資料加工和資料服務都通過一個平台來支援,必然會造成資源競爭,無法兼顧。這就好比一個飯店裡,後廚佔得地方太大,堂食的空間就小了,能夠同時響應的消費者數量必然受到限制。 資料倉儲的資料加工是層層遞進、環環相扣的方式,有著嚴格的加工流程,並且涉及到多個角色的互相配合,任何一個資料分析需求,從需求的提出到最終實現,快的要好幾周,慢的要好幾個月,自然是跟不上業務的快速變化。客戶到了飯店,只要是想點個菜單上沒有的菜品,飯店都需要把買菜、洗菜、配菜、炒菜這些環節都走一遍,上菜起碼得等2、3個小時甚至是第二天才有,沒有哪個食客能忍受的了吧。 很多數倉採用資料驅動的建設方式,不管是不是需要的資料,先往倉庫里放,總覺得以後會用的上,導致倉庫規模極速膨脹,並且存在大量無產出資料,運維成本和難度非常大。就好像開個飯店不管客人喜歡吃什麼,先把能買到的菜都買來,拋開成本不說,光是運輸、清洗、倉儲的工作量就能把人給耗死。 數倉建設有著成熟完善的資料治理配套理論,什麼元資料管理、資料標準管理、資料質量管理等等,但是這些理論的落地往往最走變成了一紙規範,卻沒法和資料倉儲建設過程有機的結合,最後變成了你定你的規範,我建我的系統,或者是我先建系統,你再定規範,隨著系統越來越龐大,沒人能夠很清楚的知道倉庫里到底有什麼,整個數倉自然就變的難以管理和使用。 於是,雖然資料倉儲進行了數十年的發展,很多企業也是花了大量的人力和成本來進行資料倉儲系統的建設,但缺乏敏捷性的平台建設方式,自主選擇少,服務響應慢,各類資料消費者的滿意度始終都不高。 因此,慢慢的,很多企業中的資料倉儲系統,開始變得有點古代皇宮御膳房的味道,彙集各種食材,對於食材、流程、樣式有著嚴格的加工規範,充分保證了菜品的質量和水準,但是其上菜速度、翻台率以及能夠服務的食客數量都受到了極大的限制,所以只有能力為特定群體(皇家)提供各種特定的菜品。 所以,雖然資料倉儲對於資料存儲、資料採集、資料加工、資料清理這些方面發展了成熟的方法論(相當於專業的飯店後廚管理理論),但對於滿足各種靈活、敏捷、普及的資料分析需求,其作用一直是被詬病的。 而進入到今天的大數據應用時代,這個弊病就更加的明顯。 大數據浪潮帶來的挑戰不僅僅是資料量的爆髮式增長,更重要的是把個人、企業、政府對資料、資料分析的重視性提升到了前所未有的高度,整個社會對資料分析的需求也呈現爆髮式的增長。所以,Gartner提出了平民資料科學家(citizen data scientist)的概念,更有廠商和業內大牛喊出了「人人都是資料分析師」的口號。 企業如何滿足成千上萬的內部員工對於資料分析的需求?企業如何滿足千萬級以上的外部客戶對於資料分析的需求?政府如何滿足上億的社會大眾對於資料分析的需求?這成了大數據時代的資料架構師們需要去回答的問題。 […]
資料清理了解一下! 準備做數據專案的人要做好心理準備,你可能要規劃至少70%的時間在這上面,相信我,這樣的時間安排你不會後悔! 資料清理是對各種臟數據進行處理,得到乾淨的、完整的、正確的、統一的數據,為後續的數據探勘、建模分析提供基礎的,同時也是各個獨立的資訊系統之間進行溝通的基礎。這一步做不好,你會發現千辛萬苦優化演算法、統計分析、視覺化展示,到頭來是垃圾進垃圾出,沒有任何意義,還要被罵慘! 資料清理中常常遇到這些讓人頭疼的問題,我遇到許多IT同行都曾和我抱怨過,我在自己做專案的過程中更是深有體會。今天分享給大家: 1、數據來源廣,儲存方式不同 企業數位化過程中導入了ERP、CRM、OA、MES、HR、財務、行銷等等系統以幫助企業更好的發展業務、服務客戶、管理企業,這些系統產生的數據往往儲存在不同的資料庫中,還有很多企業存在大量的excel、文本、日誌甚至是紙質的資料,我們需要把這些不同結構、不同來源的資料先整合成一致的。 某服裝企業IT架構 使用FineReport報表軟體將積累的excel資料匯入資料庫中 2、數據定義不統一 同一個指標,在不同的系統不同的人群中定義內涵是不同的。這就是我們通常所說的主數據進行統一管理,列出需要分析的所有指標,確保無論什麼部門什麼系統都統一定義。 在做一個零售服裝企業專案時就遇到這樣的問題。「斷碼」這個指標在不同系統不同業務人員那裡的定義不一樣:從管理層來講,公司倉儲的服裝全部尺碼如果不完整就是斷碼;從倉庫的倉管員角度來講,倉庫內的服裝尺碼不全就是斷碼;從門店的業務員角度來講,客戶需要的尺碼當前門店無貨就是斷碼。之前會員系統、庫存系統、訂單系統並未完成主數據管理,那麼就會存在倉庫有貨,但是門店對不上貨,無法從倉庫及時取到對應貨品提供給顧客。 零售業指標體系 3、數據不完整 收集到的資料一部分完整一部分缺失。比如會員數據中,一部分會員缺少年齡、性別資料,另一部分缺少手機、地址資料。這是在數據收集、數據儲存等過程中發生的問題,要決定是要補全、棄用、重新收集或是怎樣處理。 例如從身份證號碼中獲取缺少的年齡、性別資料 4、數據重複和錯誤 同一類數據可能會在幾個資料庫中都有存儲,造成數據重複。比如每日銷售數據在銷售、市場、財務的系統中都有存儲,整合之後很多重複。如果這些重複是一致的還好,如果出現不一致,就是數據錯誤問題,以哪個系統的數據為準?數據錯誤往往也出現在數據收集時,沒有做好數據入庫的合法性校驗。比如在產品入庫時,倉庫管理員錄入產品資料時,產品名稱使用了錯別字、產品數量多加了個0等。這個需要去批量處理錯別字,與物流系統資料作對比更正。當然,最好的方法是在數據收集階段就做好把關。 填寫供應商資料時校驗是否填寫錯誤,提供校驗、保存、提交、審核、駁回、發布等完整的流程處理 5、數據收集與變化 以上好幾條內容都提到數據收集,這確實是控制垃圾數據的最重要的一道防線。數據收集要完整,後續補救很難,所以新項目需要收集資料時一定要與使用者充分討論,寧可收集多了不能落掉。數據收集要做合法性校驗,年齡填寫30、30歲、三十歲,想要那種格式限制好,讓客戶隨便寫後面有的頭疼了。 資料清理時還要考慮好數據的變化。一方面資料庫是動態的,新數據源源不斷大量的補充進來,要做好承接;另一方面,業務不斷變化導致數據的定義發生變化,之前「北方大區銷售額」代表北方3個城市的銷售額之和,這個月公司做了區域調整,「北方大區銷售額」這個指標表示的則是北方兩個城市的銷售額之和了,那麼就要做調整,要不然將是一團亂麻。 主數據管理流程圖,許可權統一收歸IT資訊部 最後一條,溝通溝通再溝通! 數據專案中,你要說服老闆理解和支持你,溝通數據收集者、提供者、使用者,是個很大的挑戰!
這個問題很籠統但也情有可原。現在很多企業認可了數據的價值,提升業務,降低成本,開拓新產品,減少風險等等,越來越多的企業要進行數字化轉型,要建設大數據平台,要成立大數據團隊。 說到傳統行業要搭建大數據團隊,那麼其實問題就來了: 1、為什麼要搭建大數據團隊?這個起因是什麼? 2、傳統行業,具體指的是哪個類型的行業,最好可以細分? 3、有哪些需要注意的地方?——這個是從技術角度,還是從管理角度?還是二者都有? 搭建大數據團隊起因會有以下幾種可能 1、企業的管理者意識比較超前 管理者希望提前布局大數據技術,儲備好大數據團隊,那麼需要進行大數據領域探索時就可以快速上手。 2、企業的數據存量很大 已有的Oracle、MySQL或者其他類型的資料庫已經無法承擔這種工作,隨著數據量越來越大,傳統的資料庫計算速度較慢,或者根本無法支撐。企業可能已經引入tableau、帆軟之類的報表BI工具,但是商業智慧BI工具經常「卡死」,其實不是BI工具的問題,而是底層資料庫無法支撐,急需採用大數據技術,支撐報表BI系統的需求。 架構圖 BI報表 3、數據存量雖然不大,但是數據增量很快 那麼這時候就「著急」了,希望儘快研究大數據技術,進行遷移,否則後面資料庫扛不住。 已上幾種情況都是需要採用大數據技術的,那麼是否需要搭建大數據團隊來實現,這又要看其他幾個問題了: 1、業務部門有無大數據訴求? 這裡並不是說業務部門希望使用什麼大數據技術,而是說業務部門希望某個模塊希望更「智慧」,例如有商品推薦、有實時告警、有更快的生產經營分析報表……,種種訴求都是業務訴求,但是既有的技術無法支撐,這時候就需要引入大數據技術; 通常,業務訴求是大數據的出發點,也是最終目標,也是讓老闆看到「價值」的地方,如果搭建了大數據團隊,研究了大數據技術,卻沒有解決業務問題,老闆會覺得這是成本的浪費。 2、業務部門的訴求細化 業務需求決定技術架構,搭建大數據團隊之前,需要先了解業務部門的規劃和訴求,基於這個訴求再來設計技術架構,技術架構的設計可以與團隊搭建並行,二者相輔相成,大數據的技術框架非常多,沒有什麼人是精通所有框架的,一般只能精通其中的一兩門就不錯了。 3、在技術架構設計之前:是否採用獨立搭建大數據平台?是否可以採用公有雲平台? 獨立搭建的特點是數據自有,且可以深入研究大數據技術,比較適合規模較大,技術能力強的企業;採用公有雲平台,特點是不用理解技術,只需將數據傳遞到公有雲服務商即可( Amazon、Microsoft、Google、阿里······); 4、技術架構的設計 如果確定不採用公有雲的話,就是自己搭建大數據平台,那麼就理清楚以下幾個問題:數據在哪裡?數據平台的建設需要哪些組件?是否需要實時計算、是否需要離線計算、是否需要互動式查詢?有哪些數據分析主題?數據倉庫怎麼搭?…… 這裡是技術架構了,這並不矛盾,就像剛才說的,技術架構與人才團隊建設需要並行。 5、已有團隊的人員組成情況 筆者參與的多個專案中都會遇到,對接的客戶都是傳統企業,對ERP技術挺了解的,寫SQL也還行,但是大數據技術就很不了解了,解決辦法有2種,第一是招人,從外面招聘大數據開發或架構師,第二是直接採購商用的易用的大數據應用平台。 對第一種方法有好處也有壞處:好處是招來的人是自有人員,相當於企業自己掌握了這門技術,這種比較適合金融、運營商或財力雄厚、IT基礎設施比較好的大型企業;弊端是招聘可能並不容易,大數據的優秀人才一般集中在互聯網領域,跳槽到傳統企業的可能並不多。 第二種方法是採購已有的商用平台,這種方式與作者的問題並不偏題。市面上有很多成熟的商用大數據應用平台,Cloudera、Hortonworks、華為等等,都有對應的產品線。 如果是自己搭建大數據團隊需要注意哪些問題呢? 我認為,傳統企業在搭建大數據團隊時,要做到以下幾點: 1、老大不參與?那可不行 「屁股決定腦袋」,具體辦事人員往往難以在全局和宏觀的高度把握大數據對於一個企業的應用規劃和價值。 企業推行大數據應用的最終目的,是要讓它成為公司決策的「大腦」、市場銷售的「指揮棒」,說到底,大數據要能夠支撐方方面面的工作,是整個企業級別的大事。 所以,大數據戰略的推進,需要企業領導者充分參與,才能保證不跑偏。否則,大數據專案只會沿襲舊有的運營模式或流於形式。 2、先內部「組隊」,專家只能做「外援」 企業做大數據要先組隊:除了「外援」,自己企業里搞IT建設的、做市場的、做銷售的、做服務的、搞管理的都得配上。簡單來說,就是這個隊伍里,必須有「做數據」的人、「分析數據」的人和「用數據」的人。 「外援」總歸是要離開的,只有通過大數據的前期實施,實現自己大數據團隊的快速成長,最終才能達到自有團隊獨立、持續應用大數據的目標。 3、先嘗嘗大數據的「味道」,再談怎麼做 很多企業做大數據,一開始就大張旗鼓做建設。要知道大數據平台一旦建起來,若是不好用或是有問題,再來改,搞不好就是全盤顛覆。 所以,建議在建大數據平台之前,先花一點時間做大數據的嘗試。比如對於要開展的一個促銷活動,給出大數據的支撐。即便是最簡單的大數據應用嘗試,也能讓我們發現搭建大數據體系時可能存在的問題。 4、做大數據就得「私人定製」 數據拿不到?流程走不通?系統和系統之間無法交互?這些看似不大的問題,卻是大數據在未來是否能夠發揮效力的底層基礎。把好企業的脈,發現潛在的問題,才能夠最大程度的發揮大數據的效力。